Designing Facebook's Photo Storage System
· 2 min read
Why Does Facebook Handle Its Own Photo Storage?
- Petabyte-scale volume of blob data
- Traditional NFS-based designs (where each image is stored as a file) face metadata bottlenecks: massive metadata severely limits metadata hit rates.
- Here are the details:
For photo applications, most metadata, such as image permissions, is useless, wasting storage space. However, the larger overhead is that the metadata of the file must be read from disk into memory to locate the file itself. While this is negligible for small-scale storage, when multiplied by billions of photos and several petabytes of data, accessing metadata becomes a throughput bottleneck.
Solution
By aggregating hundreds of thousands of images into a single Haystack storage file, the metadata burden is eliminated.
Structure
Data Layout
Index file (for quick memory loading) + Haystack storage file containing many images.
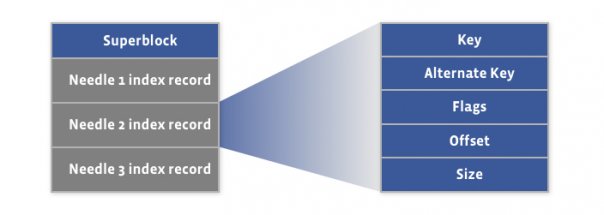
Index file layout
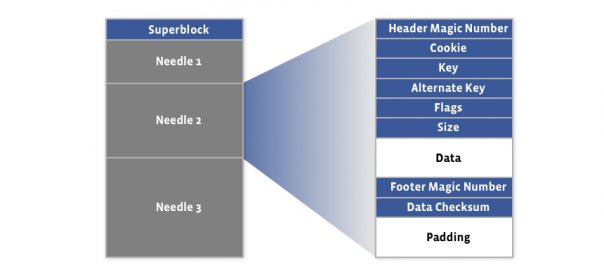
Storage file
CRUD Operations
- Create: Write to the storage file, then ==asynchronously== write to the index file, as indexing is not a critical step.
- Delete: Perform soft deletes by marking the deleted bits in a flag field. Execute hard deletes through compacting operations.
- Update: During updates, only append (append-only); if a duplicate key is encountered, the application can choose to update and read the key with the maximum offset.
- Read: Read operations (offset, key, backup key, cookie, and data size)
Use Cases
Upload
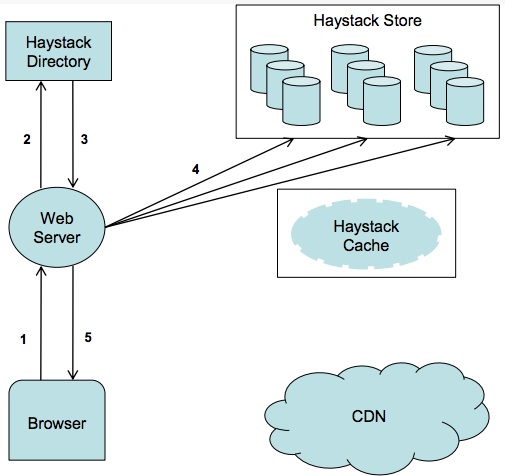
Download
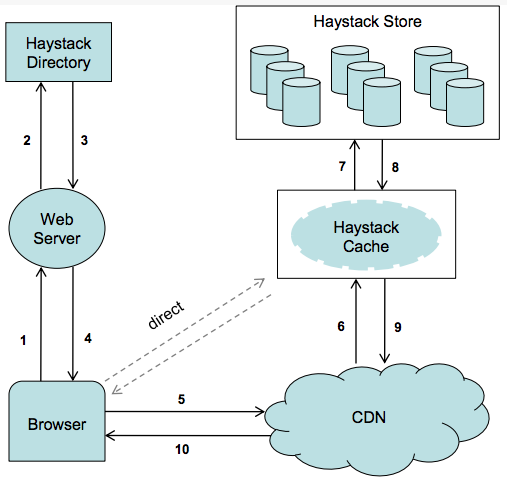
- https://www.usenix.org/conference/osdi10/finding-needle-haystack-facebooks-photo-storage
- https://www.facebook.com/notes/facebook-engineering/needle-in-a-haystack-efficient-storage-of-billions-of-photos/76191543919