Toutiao Recommendation System: P2 Content Analysis
In Toutiao Recommendation System: P1 Overview, we know that content analysis and data mining of user tags are the cornerstones of the recommendation system.
What is the content analysis?
content analysis = derive intermediate data from raw articles and user behaviors.
Take articles for example. To model user interests, we need to tag contents and articles. To associate a user with the interests of the “Internet” tag, we need to know whether a user reads an article with the “Internet” tag.
Why are we analyzing those raw data?
We do it for the reason of …
- Tagging users (user profile)
- Tagging users who liked articles with “Internet” tag. Tagging users who liked articles with “xiaomi” tag.
- Recommending contents to users by tags
- Pushing “meizu” contents to users with “meizu” tag. Pushing “dota” contents to users with “dota” tag.
- Preparing contents by topics
- Put “Bundesliga” articles to “Bundesliga topic”. Put “diet” articles to “diet topic”.
Case Study: Analysis Result of an Article
Here is an example of “article features” page. There are article features like categorizations, keywords, topics, entities.
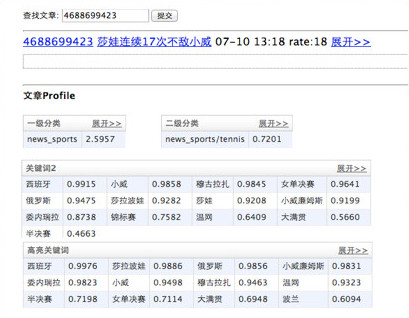
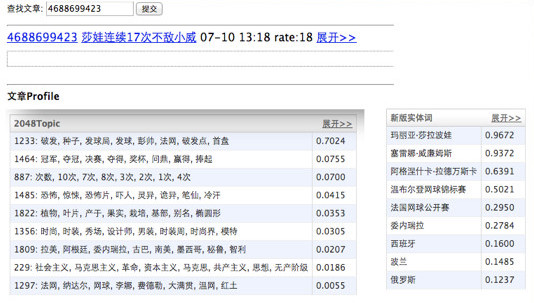
What are the article features?
-
Semantic Tags: Human predefine those tags with explicit meanings.
-
Implicit Semantics, including topics and keywords. Topic features are describing the statistics of words. Certain rules generate keywords.
-
Similarity. Duplicate recommendation once to be the most severe feedbacks we get from our customers.
-
Time and location.
-
Quality. Abusing, porn, ads, or “chicken soup for the soul”?
Article features are important
- It is not true that a recommendation system cannot work at all without article features. Amazon, Walmart, Netflix can recommend by collaborative filtering.
- However, in news product, users consume contents of the same day. Bootstrapping without article features is hard. Collaborative filtering cannot help with bootstrapping.
- The finer of the granularity of the article feature, the better the ability to bootstrap.
More on Semantic Tags
We divide features of semantic tags into three levels:
- Categorizations: used in the user profile, filtering contents in topics, recommend recall, recommend features
- Concepts: used in filtering contents in topics, searching tags, recommend recall(like)
- Entities: used in filtering contents in topics, searching tags, recommend recall(like)
Why dividing into different levels? We do this so that they can capture articles in different granularities.
- Categorizations: full in coverage, low in accuracy.
- Concepts: medium in coverage, medium in accuracy.
- Entities: low in coverage, high in accuracy. It only covers hot people, organizations, products in each area.
Categorizations and concepts are sharing the same technical infrastructure.
Why do we need semantic tags?
- Implicit semantics
- have been functioning well.
- cost much less than semantic tags.
- But, topics and interests need a clear-defined tagging system.
- Semantic tags also evaluate the capability in NPL technology of a company.
Document classification
Classification hierarchy
- Root
- Science, sports, finance, entertainment
- Football, tennis, table tennis, track and field, swimming
- International, domestic
- Team A, team B
Classifiers:
- SVM
- SVM + CNN
- SVM + CNN + RNN
Calculating relevance
- Lexical analysis for articles
- Filtering keywords
- Disambiguation
- Calculating relevance