Designing a Load Balancer
Requirements Analysis
Internet services often need to handle traffic from around the world, but a single server can only serve a limited number of requests at the same time. Therefore, we typically have a server cluster to collectively manage this traffic. The question arises: how can we evenly distribute this traffic across different servers?
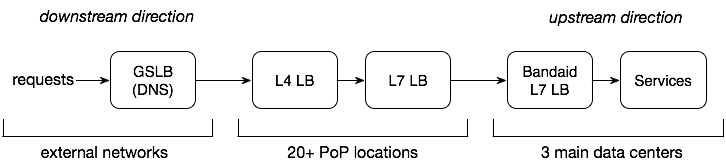
From the user to the server, there are many nodes and load balancers at different levels. Specifically, our design requirements are:
- Design a Layer 7 load balancer located internally in the data center.
- Utilize real-time load information from the backend.
- Handle tens of millions of requests per second and a throughput of 10 TB per second.
Note: If Service A depends on Service B, we refer to A as the downstream service and B as the upstream service.
Challenges
Why is load balancing difficult? The answer lies in the challenge of collecting accurate load distribution data.
Count-based Distribution ≠ Load-based Distribution
The simplest approach is to distribute traffic randomly or in a round-robin manner based on the number of requests. However, the actual load is not calculated based on the number of requests; for example, some requests are heavy and CPU-intensive, while others are lightweight.
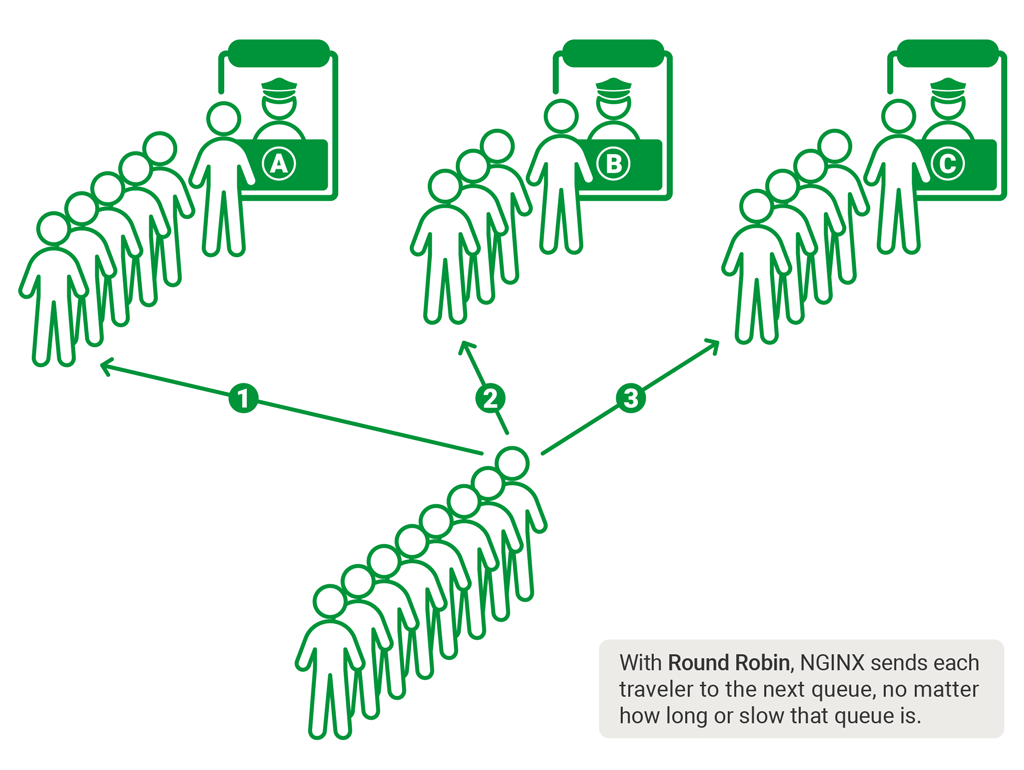
To measure load more accurately, the load balancer must maintain some local state—such as the current number of requests, connection counts, and request processing delays. Based on this state, we can employ appropriate load balancing algorithms—least connections, least latency, or random N choose one.
Least Connections: Requests are directed to the server with the fewest current connections.
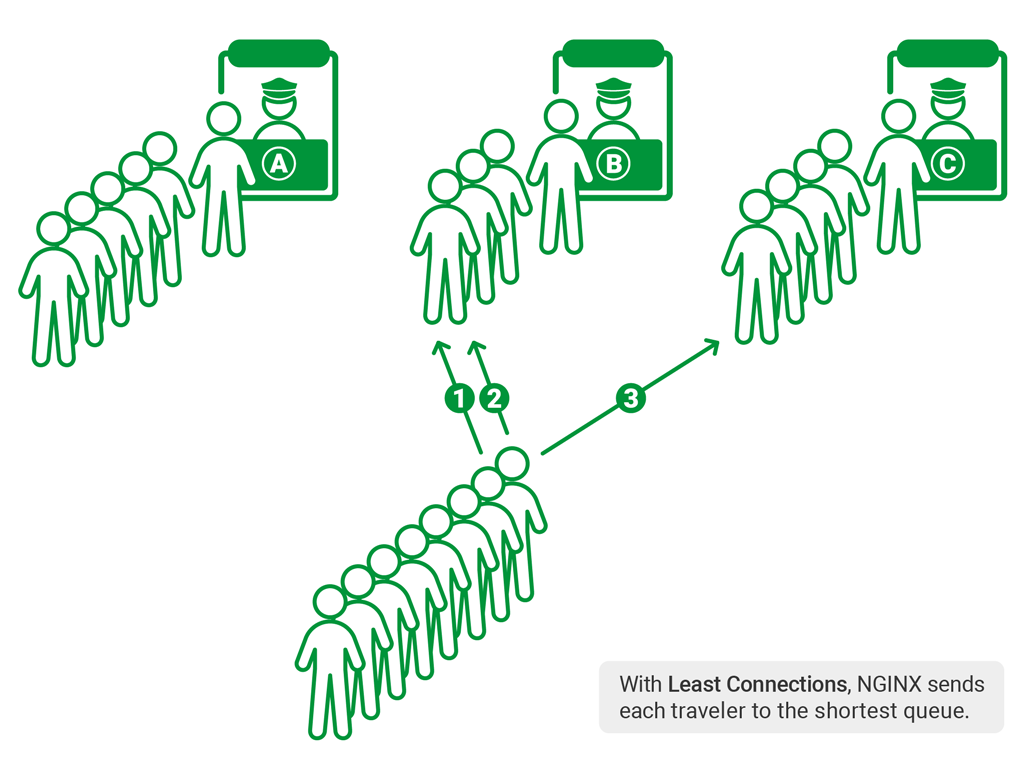
Least Latency: Requests are directed to the server with the lowest average response time and fewest connections. Servers can also be weighted.
Random N Choose One (N is typically 2, so we can also refer to it as the power of two choices): Randomly select two servers and choose the better of the two, which helps avoid the worst-case scenario.
Distributed Environment
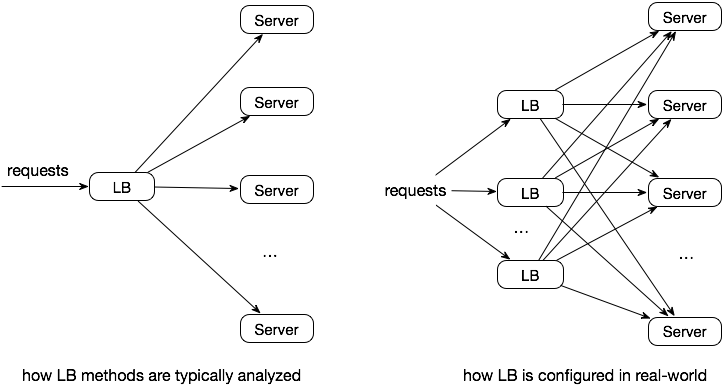
In a distributed environment, local load balancers struggle to understand the complete state of upstream and downstream services, including:
- Load of upstream services
- Upstream services can be very large, making it difficult to select an appropriate subset for the load balancer
- Load of downstream services
- The specific processing time for different types of requests is hard to predict
Solutions
There are three approaches to accurately collect load information and respond accordingly:
- A centralized balancer that dynamically manages based on the situation
- Distributed balancers that share state among them
- Servers return load information along with requests, or the balancer actively queries the servers
Dropbox chose the third approach when implementing Bandai, as it adapted well to the existing random N choose one algorithm.
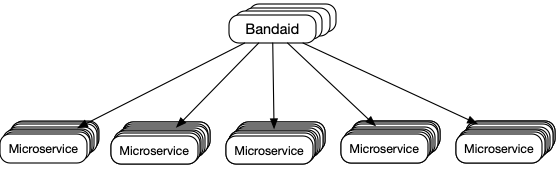
However, unlike the original random N choose one algorithm, this approach does not rely on local state but instead uses real-time results returned by the servers.
Server Utilization: Backend servers set a maximum load, track current connections, and calculate utilization, ranging from 0.0 to 1.0.
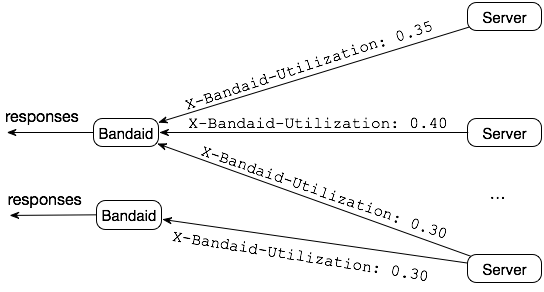
Two issues need to be considered:
- Error Handling: If fail fast, the quick processing may attract more traffic, leading to more errors.
- Data Decay: If a server's load is too high, no requests will be sent there. Therefore, using a decay function similar to a reverse S-curve ensures that old data is purged.
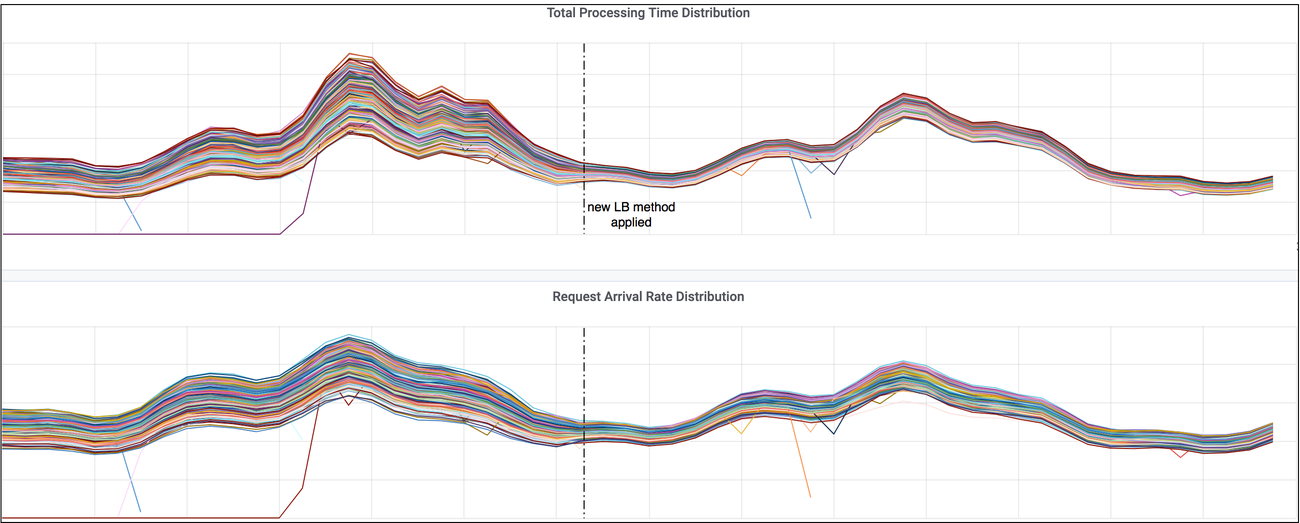
Result: Requests Received by Servers are More Balanced
- https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
- https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
- https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn