设计负载均衡器
· 阅读需 4 分钟
需求分析
互联网服务往往要处理来自全世界的流量,但是,一个服务器只能够同时服务有限数量的请求。因此,通常我们会有一个服务器集群来共同处理这些流量。那么问题来了,怎样才能够让这些流量均匀地分布到不同的服务器上呢?
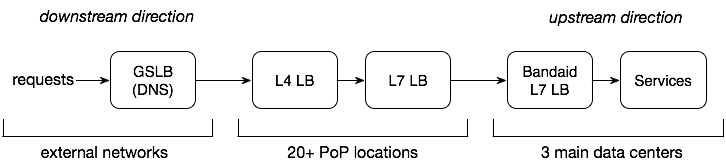
从用户到服务器,会经过很多的节点和不同层级的负载均衡器。具体来讲,我们这次设计的需求是:
- 设计第7层的负载均衡器,位于数据中心的内部。
- 利用来自后端实时的负载信息。
- 服务每秒千万级的流量以及10 TB每秒级别的吞吐量。
补充:如果服务 A 依赖服务 B,那我们称 A 是 B 的下游服务,而 B 是 A 的上游服务。
挑战
为什么负载均衡会很难做?答案是很难收集准确的负载分布数据。
按照数量分布 ≠ 按照负载分布
最简单的做法是根据请求的数量,随机地或者循环地分布流量。然而,实际的负载并不是根据请求的数量来算的,比如有些请求很重很耗CPU,有些请求很轻量级。
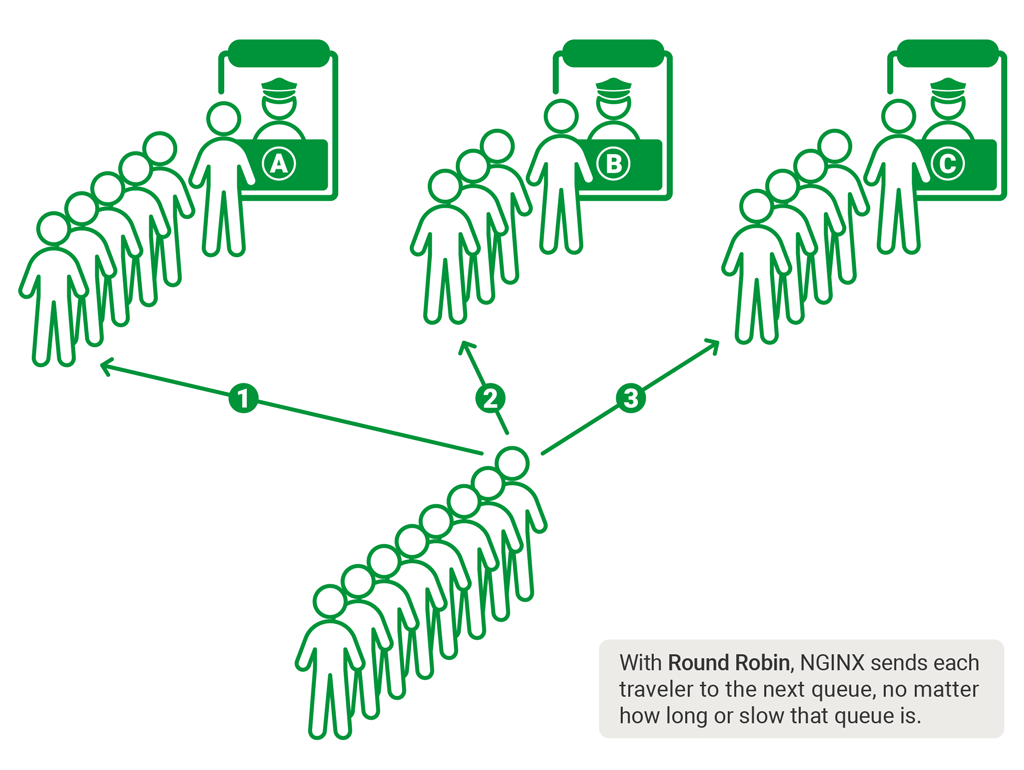
为了更加准确地衡量负载,负载均衡器得保持一些本地状态 —— 比如,存当前的请求数、连接数、请求处理的延迟。基于这些状态,我们能够使用相应的负载均衡的算法 —— 最少连接、最少延迟、随机 N 取一。
最少连接:请求会被导向当前连接数最小的服务器。
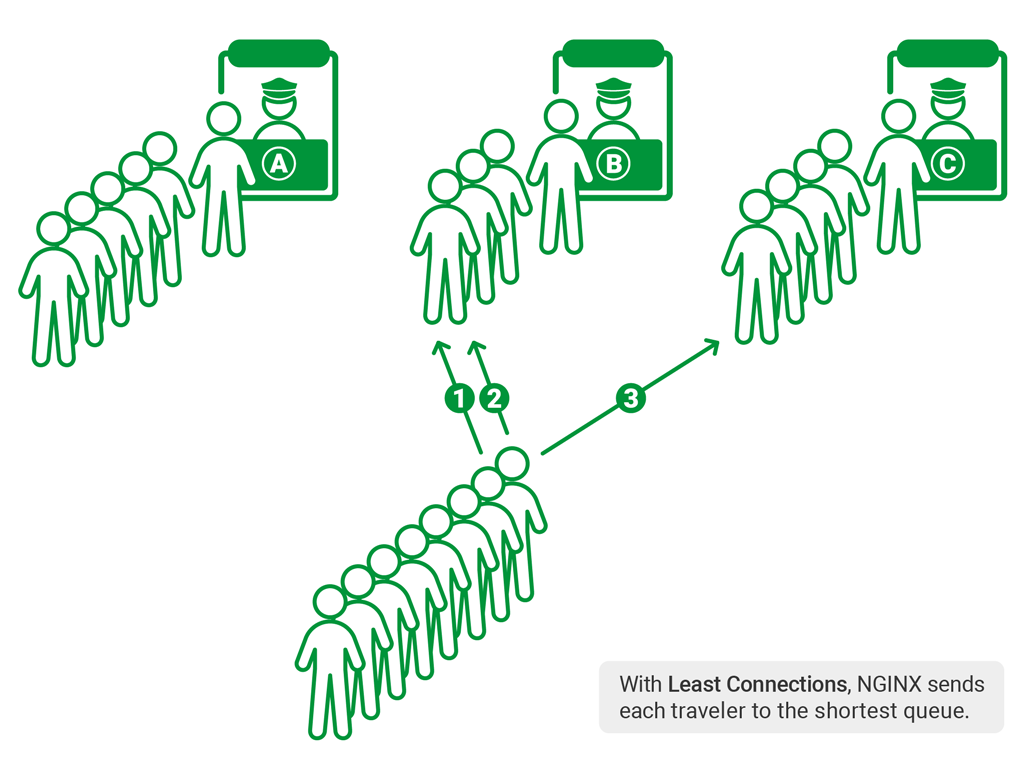
最少延迟:请求会被导向最少平均反应时长且最少连接数的服务器。还可以给服务器加权重。
随机 N 取一 (N 通常是 2,所以我们也可以称之为二选一的力量):随机的选两个服务器,取两者之中最好的,能够避免最坏的情况。
分布式的环境
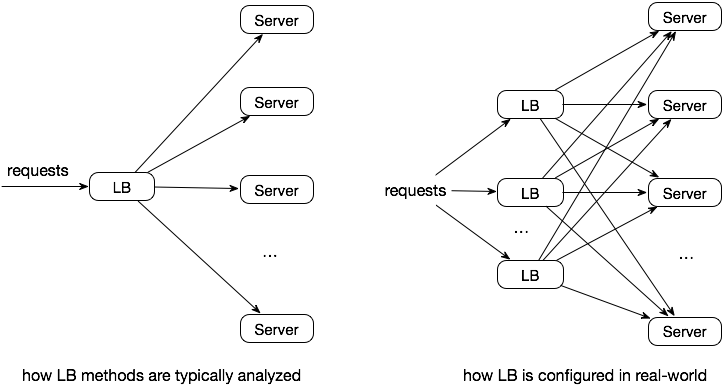
在分布式的环境中,本地的负载均衡器难移了解上下游服务完整的状态,包括
- 上游服务的负载
- 上游服务可能超级大,因此很难选择一个合适的子集接入负载均衡器
- 下游服务的负载
- 不同种类的请求的具体处理时间很难预测
解决方案
有三种方案能够准确地搜集负载的具体情况并相应地处理:
- 中心化的一个均衡器,根据情况动态地处理
- 分布式但是各个均衡器之间要共享状态
- 服务器返回请求的时候捎带上负载信息,或者是均衡器主动询问服务器
Dropbox 在做 Bandai 的时候选择了第三种方案,因为这很好地适应了现行的随机 N 选一的算法。
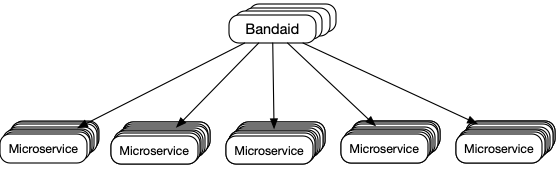
然而,与原配的随机 N 选一的算法所不同的是,不是使用本地的状态,而是选择服务器实时返回的结果。
服务器使用率:后端服务器设置了最大负载,数当前的连接,然后计算出使用率,范围是从 0.0 到 1.0.
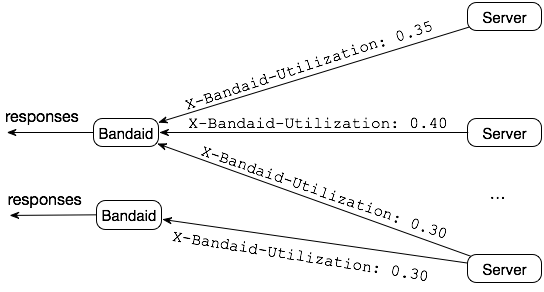
有两个问题需要考虑:
- 处理错误: 如果 fail fast ,由于处理得很快,反而会吸引更多的流量产生更多的错误。
- 数据要衰减: 如果服务器的负载太高,没有请求会发到那里。因此,使用一个类似于反 S 曲线的衰减函数来保证老数据会被清理掉。
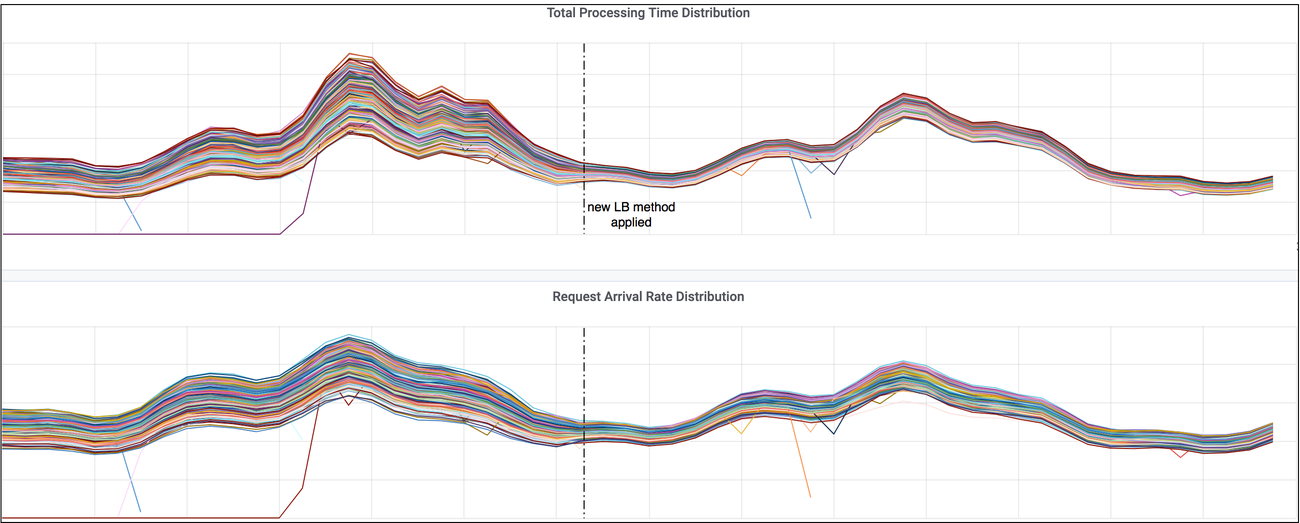
结果: 服务器接收的请求更加的均衡了
- https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
- https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
- https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn