今日头条推荐系统:P2 内容分析
在 今日头条推荐系统:P1 概述 中,我们了解到内容分析和用户标签的数据挖掘是推荐系统的基石。
什么是内容分析?
内容分析 = 从原始文章和用户行为中提取中间数据。
以文章为例。为了建模用户兴趣,我们需要对内容和文章进行标记。为了将用户与“互联网”标签的兴趣关联起来,我们需要知道用户是否阅读了带有“互联网”标签的文章。
我们为什么要分析这些原始数据?
我们这样做的原因是 …
- 标记用户(用户画像)
- 标记喜欢带有“互联网”标签的文章的用户。标记喜欢带有“小米”标签的文章的用户。
- 根据标签向用户推�荐内容
- 向带有“小米”标签的用户推送“小米”内容。向带有“Dota”标签的用户推送“Dota”内容。
- 按主题准备内容
- 将“德甲”文章放入“德甲主题”。将“饮食”文章放入“饮食主题”。
案例研究:一篇文章的分析结果
以下是“文章特征”页面的示例。文章特征包括分类、关键词、主题、实体。
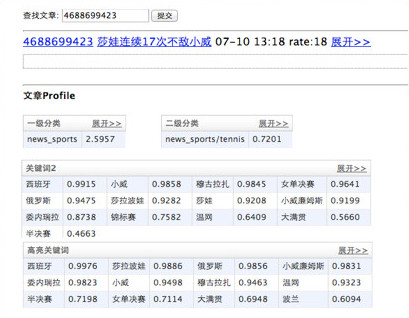
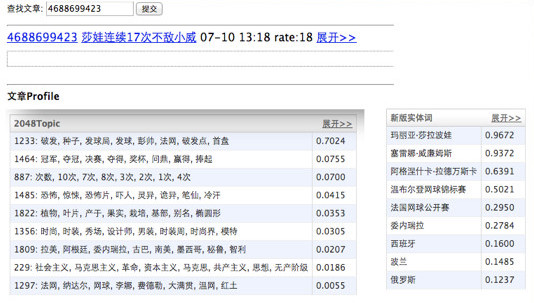
文章特征是什么?
-
语义标签:人类预定义这些标签,具有明确的含义。
-
隐含语义,包括主题和关键词。主题特征描述了单词的统计数据。某些规则生成关键词。
-
相似性。重复推荐曾是我们从客户那里获得的最严重反馈之一。
-
时间和地点。
-
质量。滥用、色情、广告或“心灵鸡汤”?
文章特征的重要性
- 并不是说没有文章特征推荐系统就完全无法工作。亚马逊、沃尔玛、Netflix可以通过协同过滤进行推荐。
- 然而,在新闻产品中,用户消费的是当天的内容。没有文章特征的引导是困难的。协同过滤无法帮助引导。
- 文章特征的粒度越细,启动的能力就越强。
更多关于语义标签的信息
我们将语义标签的特征分为三个层次:
- 分类:用于用户画像、过滤主题内容、推荐召回、推荐特征
- 概念:用于过滤主题内容、搜索标签、推荐召回(喜欢)
- 实体:用于过滤主题内容、搜索标签、推荐召回(喜欢)
为什么要分成不同的层次?我们这样做是为了能够以不同的粒度捕捉文章。
- 分类:覆盖全面,准确性低。
- 概念:覆盖中等,准确性中等。
- 实体:覆盖低,准确性高。它仅覆盖每个领域的热门人物、组织、产品。
分类和概念共享相同的技术基础设施。
我们为什么需要语义标签?
- 隐含语义
- 一直运作良好。
- 成本远低于语义标签。
- 但是,主题和兴趣需要一个明确的标签系统。
- 语义标签还评估公司的NPL技术能力。
文档分类
分类层级
- 根
- 科学、体育、金融、娱乐
- 足球、网球、乒乓球、田径、游泳
- 国际、国内
- A队、B队
分类器:
- SVM
- SVM + CNN
- SVM + CNN + RNN
计算相关性
- 对文章进行词汇分析
- 过滤关键词
- 消歧义
- 计算相关性