设计 Pinterest
系统设计面试是为了让人们找到能够独立设计和实施互联网服务的团队成员。面试是展示你“工程能力”的绝佳机会——你必须将你的知识与决策能力结合起来,为正确的场景设计合适的系统。
为你的受众发出正确的信号
关于系统设计面试,你需要知道的第一件事是,你必须在整个面试过程中保持健谈。当然,你必须咨询面试官,以确定你是否在正确的轨道上,能够满足他们的需求;然而,你仍然需要证明你可以独立完成工作。因此,理想情况下,在面试过程中,你应该不断谈论面试官所期望的内容,甚至在他们提出问题之前。
其次,不要仅限于一种解决方案。面对同样的问题,可能有很多种解决方法,成为工程师并不需要许可证。你所做的所有选择都有利弊。与面试官讨论权衡,并选择最适合你假设和约束条件的解决方案。这就像在现实世界中,人们不会在沟渠上建造金门大桥,也不会在旧金山湾上建造临时桥。
最后,要在面试中表现出色,你最好带来一些新东西。“优秀的工程师�编写脚本;伟大的工程师创新”。如果你不能教会人们一些新东西,你只是优秀,而不是伟大。优质答案 = 新颖性 x 共鸣。
4 步模板
如果你不确定如何在面试中保持健谈,这里有一个简单的 4 步模板,你可以以分而治之的方式遵循:
- 澄清需求并做出假设。
- 勾勒出高层设计。
- 深入各个组件及其相互作用。
- 总结盲点或瓶颈。
本书中的所有设计都将遵循这些步骤。
特别是对于这个“设计 Pinterest”,我将尽可能详细地解释一切,因为这是整本书的第一个案例。然而,为了简单起见,我不会在本书的其他设计中涵盖许多元素。
设计 Pinterest
第一步:澄清需求并做出假设
所有系统存在都是有目的的,软件系统也是如此。同时,软件工程师不是艺术家——我们构建东西是为了满足客户的需求。因此,我们应该始终从客户出发。同时,为了将设计适应 45 分钟的会议,我们必须通过做出假设来设定约束和范围。
Pinterest 是一个高度可扩展的照片分享服务,拥有数亿月活跃用户。以下是需求:
- 最重要的功能
- 新闻推送:客户登录后会看到一系列图像。
- 一个客户关注其他客户以订阅他们的推送。
- 上传照片:他们可以上传自己的图像,这些图像会出现在关注者的推送中。
- 扩展性
- 功能和开发产品的团队太多,因此产品被解耦为微服务。
- 大多数服务应具有水平扩展性和无状态性。
第二步:勾勒出高层设计
在勾勒出大局之前,不要深入细节。 否则,走错方向会浪费时间,并阻止你完成任务。
这是高层架构,其中箭头表示依赖关系。(有时,人们会使用箭头来描述数据流的方向。)

第三步:深入各个组件及其相互作用
一旦架构确定,我们可以与面试官确认他们是否希望与你一起深入探讨每个组件。有时,面试官可能希望聚焦于一个意想不到的领域问题,比如设计照片存储(这就是我总是说没有一种适合所有的系统设计解决方案的原因。继续学习...)。然而,在这里,我们仍然假设我们正在构建核心抽象:上传照片,然后发布给关注者。
再次强调,我将尽可能多地以自上而下的顺序进行解释,因为这是我们的第一个设计示例。在现实世界中,你不必逐个组件地详细讨论;相反,你应该首先关注核心抽象。
移动和浏览器客户端通过边缘服务器连接到 Pinterest 数据中心。边缘服务器是提供网络入口的边缘设备。在图中,我们看到两种类型的边缘服务器——负载均衡器和反向代理。
负载均衡器(LB)
负载均衡器将传入的网络流量分配给一组后端服务器。它们分为三类:
- DNS 轮询(很少使用):客户端获得随机顺序的 IP 地址列表。
- 优点:易于实现,通常免费。
- 缺点:难以控制,响应性不强,因为 DNS 缓存需要时间过期。
- L3/L4 网络层负载均衡器:流量通过 IP 地址和端口路由。L3 是网络层(IP)。L4 是传输层(TCP)。
- 优点:更好的粒度,简单,响应迅速。例如,根据端口转发流量。
- 缺点:内容无关:无法根据数据的内容路由流量。
- L7 应用层负载均衡器:流量根据 HTTP 协议内部的内容进行路由。L7 是应用层(HTTP)。如果面试官想要更多,我们可以建议具体的算法,如轮询、加权轮询、最少负载、最少负载与慢启动、利用率限制、延迟、级联等。查看设计 L7 负载均衡器以了解更多。
负载均衡器可以存在于许多其他地方,只要有平衡流量的需求。
反向代理
与位于客户端前面的“正向”代理不同,反向代理是一种位于服务器前面的代理,因此称为“反向”。根据这个定义,负载均衡器也是一种反向代理。
反向代理根据使用方式带来了许多好处,以下是一些典型的好处:
- 路由:将流量集中到内部服务,并为公众提供统一的接口。例如,www.example.com/index 和 www.example.com/sports 看似来自同一个域,但这些页面来自反向代理后面的不同服务器。
- 过滤:过滤掉没有有效凭证的请求,以进行身份验证或授权。
- 缓存:某些资源对 HTTP 请求非常受欢迎,因此你可能希望为该路由配置一些缓存,以节省一些服务器资源。
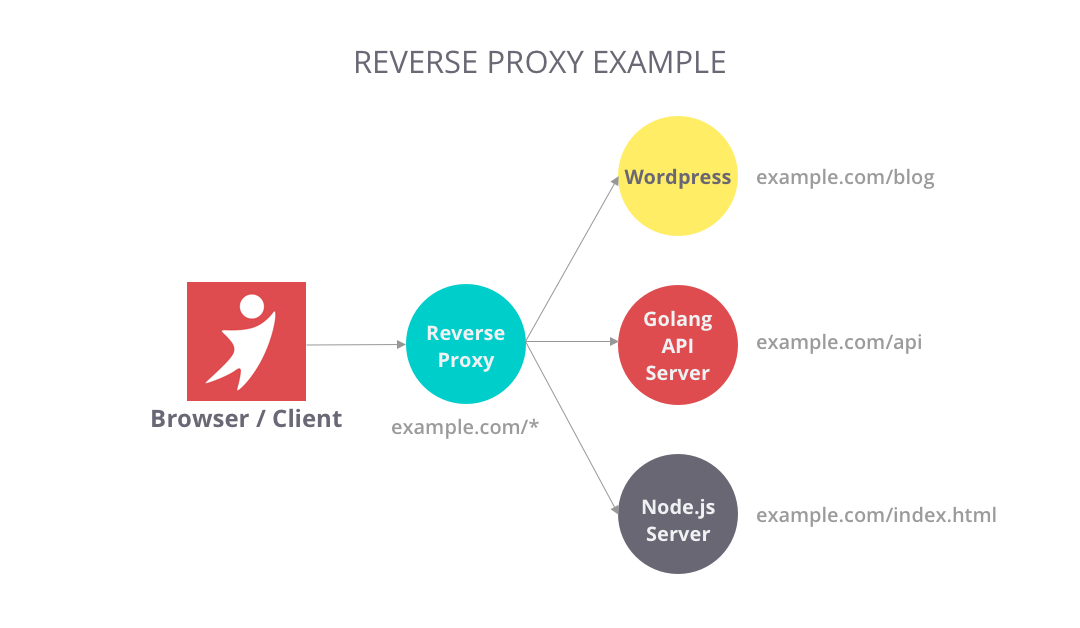
Nginx、Varnish、HAProxy 和 AWS 弹性负载均衡是市场上流行的产品。我发现编写一个轻量级反向代理在 Golang 中既方便又强大。在 Kubernetes 的上下文中,这基本上就是 Ingress 和 Ingress 控制器所做的。
Web 应用
这是我们提��供网页的地方。在早期,网络服务通常将后端与页面渲染结合在一起,如 Django 和 Ruby on Rails 框架所做的。后来,随着项目规模的增长,它们通常被解耦为专用的前端和后端项目。前端专注于应用渲染,而后端为前端提供 API 供其使用。
移动应用
大多数后端工程师对移动设计模式不熟悉,可以查看 iOS 架构模式。
专用的前端 Web 项目与独立的移动应用非常相似——它们都是服务器的客户端。有些人会称它们为“整体前端”,当工程师能够同时在两个平台上构建用户体验时,比如 Web 的 React 和移动的 React-Native。
API 应用
客户端通过公共 API 与服务器通信。如今,人们通常提供 RESTful 或 GraphQL API。了解更多信息,请查看公共 API 选择。
无状态 Web 和 API 层
整个系统有两个主要瓶颈——负载(每秒请求数)和带宽。 我们可以通过以下方式改善情况:
- 使用更高效的软件,例如使用具有异步和非阻塞反应器模式的框架,或者
- 使用更多硬件,例如
- 向上扩展,即垂直扩展:使用更强大的机器,如超级计算机或大型机,或
- 向外扩展,即水平扩展:使用更多数量的低成本机器。
互联网公司更倾向于水平扩展,因为
- 使用大量商品机器更具成本效益。
- 这也有利于招聘——每个人都可以用一台 PC 学习编程。
为了水平扩展,我们最好保持服务无状态,这意味着它们不在本地内存或存储中保存状态,因此我们可以随时意外终止或重新启动它们。
了解更多关于扩展的信息,请查看如何扩展 Web 服务。
服务层
单一责任原则提倡小型和自主的服务协同工作,以便每个服务可以“做好一件事并做好”,并独立增长。拥有小型服务的小团队可以更积极地规划超高速增长。了解更多关于微服务与单体服务的信息,请查看设计 Uber。
服务发现
这些服务如何找到彼此?
Zookeeper 是一个流行的集中式选择。每个服务的实例(名称、地址、端口等)注册到 ZooKeeper 的路径中��。如果一个服务不知道如何找到另一个服务,它可以查询 Zookeeper 以获取位置,并在该位置不可用之前记住它。
Zookeeper 是一个 CP 系统,根据 CAP 定理(有关更多讨论,请参见第 2.3 节),这意味着在发生故障时它保持一致性,但集中共识的领导者将无法注册新服务。
与 Zookeeper 相比,Uber 以去中心化的方式做了一些有趣的工作,称为hyperbahn,基于Ringpop 一致性哈希环,尽管最终被证明是一个巨大的失败。阅读亚马逊的 Dynamo以理解 AP 和最终一致性。
在 Kubernetes 的上下文中,我想使用服务对象和 Kube-proxy,因此程序员可以轻松指定目标服务的地址,使用内部 DNS。
关注者服务
关注者和被关注者之间的关系围绕这两个简单的数据结构:
Map<Followee, List of Followers>Map<Follower, List of Followees>
像 Redis 这样的键值存储非常适合这里,因为数据结构相当简单,并且该服务应该是关键任务,具有高性能和低延迟。
关注者服务为关注者和被关注者提供功能。为了使图像出现在推送中,有两种模型可以实现。
- 推送。一旦图像上传,我们将图像元数据推送到所有关注者的推送中。关注者将直接看到其准备好的推送。
- 如果
Map <Followee, List of Followers>的扇出太大,则推送模型将消耗大量时间和数据重复。
- 如果
- 拉取。我们不提前准备推送;相反,当关注者检查其推送时,它获取关注者列表并获取他们的图像。
- 如果
Map<Follower, List of Followees>的扇出太大,则拉取模型将花费大量时间遍历庞大的关注者列表。
- 如果
推送服务
推送服务在数据库中存储图像帖子的元数据,如 URL、名称、描述、位置等,而图像本身通常保存在像 AWS S3 和 Azure Blob 存储这样的 Blob 存储中。以 S3 为例,当客户通过 Web 或移动客户端创建帖子时,可能的解决方案如下:
- 服务器生成一个 S3 预签名 URL,授予写入权限。
- 客户端使用生成的预签名 URL 将图像二进制文件上传到 S3。
- 客户端将帖子和图像元数据提交给服务器,然后触发数据管道,如果存在推送模型,则将帖子推送到关注者的推送中。
客户随着时间的推移向推送中发布,因此 HBase / Cassandra 的时间戳索引非常适合此用例。
图像 Blob 存储和 CDN
传输 Blob 消耗大量带宽。一旦我们上传了 Blob,我们会频繁读取它们,但很少更新或删除它。因此,开发人员通常使用 CDN 来缓存它们,这将把这些 Blob 分发到离客户更近的地方。
AWS CloudFront CDN + S3 可能是市场上最流行的组合。我个人使用 BunnyCDN 来处理我的在线内容。Web3 开发人员喜欢使用像 IPFS 和 Arware 这样的去中心化存储。
搜索服务
搜索服务连接到所有可能的数据源并对其进行索引,以便人们可以轻松搜索推送。我们通常使用 ElasticSearch 或 Algolia 来完成这项工作。
垃圾邮件服务
垃圾邮件服务使用机器学习技术,如监督学习和无监督学习,来标记和删除不当内容和虚假账户。了解更多信息,请查看使用半监督学习的欺诈检测。
第四步:总结盲点或瓶颈。
上述设计的盲点或瓶颈是什么?
- 截至 2022 年,人们发现使用关注者-被关注者的方式组织推送不太可取,因为这对新客户来说很难启动,对现有客户来说也很难找到更有趣的内容。TikTok 和 Toutiao 引领了通过推荐算法组织推送的新一波创新。然而,这个设计并没有涵盖推荐系统的部分。
- 对于一个流行的基于照片的社交网络,扩展是系统面临的最大挑战。因此,为了确保设计能够承受�负载,我们需要进行容量规划。
使用电子表格和简单计算进行容量规划
我们可以通过两种方向来接近估算问题:自下而上和自上而下。
对于自下而上,你可以对现有系统进行负载测试,并根据公司的当前性能和未来增长率进行未来规划。
对于自上而下,你从理论上的客户开始,并进行简单的计算。我强烈建议你使用数字电子表格,在那里你可以轻松列出公式和假设/计算的数字。
当我们依赖外部 Blob 存储和 CDN 时,带宽不太可能成为问题。因此,我将以关注者服务为例估算容量:
| 行 | 描述(“/”表示每) | 估算数量 | 计算结果 |
|---|---|---|---|
| A | 每日活跃用户 | 33,000,000 | |
| B | 每用户每天请求数 | 60 | |
| C | 每台机器的请求数 | 10,000(c10k 问题) | |
| D | 扩展系数 (用户增长的冗余) | 3 倍 | |
| E | 服务实例数量 | = A * B / (24 * 3600) / C * D | ~= 7 |
我们可以看到 行 E 是公式的计算结果。在对每个微服务和存储应用此估算方法后,我们将更好地理解整个系统。
现实世界的容量规划不是一次性的交易。准备过多的机器会浪费资金,而准备过少的机器会导致停机。我们通常会进行几轮估算和实验,以找到正确的答案;或者如果系统支持并且预算不是问题��,则使用自动扩展。
大型公司的工程师通常享受丰富的计算和存储资源。然而,优秀的工程师会考虑成本和收益。我有时会尝试不同等级的机器,并为它们的月度支出添加行以进行估算。