Toutiao Recommendation System: P1 Overview
What are we optimizing for? User Satisfaction
We are finding the best function below to maximize user satisfaction .
user satisfaction = function(content, user profile, context)
- Content: features of articles, videos, UGC short videos, Q&As, etc.
- User profile: interests, occupation, age, gender and behavior patterns, etc.
- Context: Mobile users in contexts of workspace, commuting, traveling, etc.
How to evaluate the satisfaction?
-
Measurable Goals, e.g.
- click through rate
- Session duration
- upvotes
- comments
- reposts
-
Hard-to-measurable Goals:
- Frequency control of ads and special-typed contents (Q&A)
- Frequency control of vulgar content
- Reducing clickbait, low quality, disgusting content
- Enforcing / pining / highly-weighting important news
- Lowly-weighting contents from low-level accounts
How to optimize for those goals? Machine Learning Models
It is a typical supervised machine learning problem to find the best function above. To implement the system, we have these algorithms:
- Collaborative Filtering
- Logistic Regression
- DNN
- Factorization Machine
- GBDT
A world-class recommendation system is supposed to have the flexibility to A/B-test and combine multiple algorithms above. It is now popular to combine LR and DNN. Facebook used both LR and GBDT years ago.
How do models observe and measure the reality? Feature engineering
-
Correlation, between content’s characteristic and user’s interest. Explicit correlations include keywords, categories, sources, genres. Implicit correlations can be extract from user’s vector or item’s vector from models like FM.
-
Environmental features such as geo location, time. It’s can be used as bias or building correlation on top of it.
-
Hot trend. There are global hot trend, categorical hot trend, topic hot trend and keyword hot trend. Hot trend is very useful to solve cold-start issue when we have little information about user.
-
Collaborative features, which helps avoid situation where recommended content get more and more concentrated. Collaborative filtering is not analysing each user’s history separately, but finding users’ similarity based on their behaviour by clicks, interests, topics, keywords or event implicit vectors. By finding similar users, it can expand the diversity of recommended content.
Large-scale Training in Realtime
- Users like to see news feed updated in realtime according to what we track from their actions.
- Use Apache storm to train data (clicks, impressions, faves, shares) in realtime.
- Collect data to a threshold and then update to the recommendation model
- Store model parameters , like tens of billions of raw features and billions of vector features, in high performance computing clusters.
They are implemented in the following steps:
- Online services record features in realtime.
- Write data into Kafka
- Ingest data from Kafka to Storm
- Populate full user profiles and prepare samples
- Update model parameters according to the latest samples
- Online modeling gains new knowledge
How to further reducing the latency? Recall Strategy
It is impossible to predict all the things with the model, considering the super-large scale of all the contents. Therefore, we need recall strategies to focus on a representative subset of the data. Performance is critical here and timeout is 50ms.
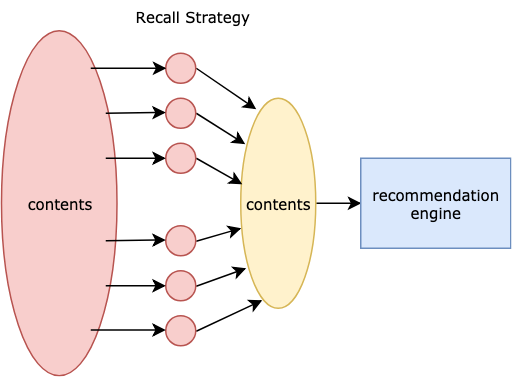
Among all the recall strategies, we take the InvertedIndex<Key, List<Article>> .
The Key can be topic, entity, source, etc.
| Tags of Interests | Relevance | List of Documents |
|---|---|---|
| E-commerce | 0.3 | … |
| Fun | 0.2 | … |
| History | 0.2 | … |
| Military | 0.1 | … |
Data Dependencies
- Features depends on tags of user-side and content-side.
- recall strategy depends on tags of user-side and content-side.
- content analysis and data mining of user tags are cornerstone of the recommendation system.
What is the content analysis?
content analysis = derive intermediate data from raw articles and user behaviors.
Take articles for example. To model user interests, we need to tag contents and articles. To associate a user with the interests of the “Internet” tag, we need to know whether a user reads an article with the “Internet” tag.
Why are we analyzing those raw data?
We do it for the reason of …
- Tagging users (user profile)
- Tagging users who liked articles with “Internet” tag. Tagging users who liked articles with “xiaomi” tag.
- Recommending contents to users by tags
- Pushing “meizu” contents to users with “meizu” tag. Pushing “dota” contents to users with “dota” tag.
- Preparing contents by topics
- Put “Bundesliga” articles to “Bundesliga topic”. Put “diet” articles to “diet topic”.
Case Study: Analysis Result of an Article
Here is an example of “article features” page. There are article features like categorizations, keywords, topics, entities.
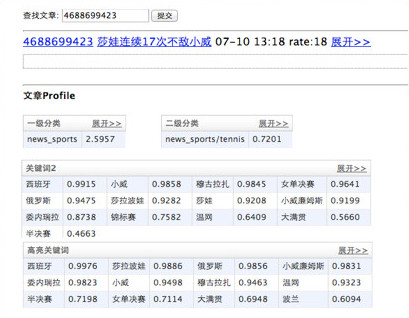
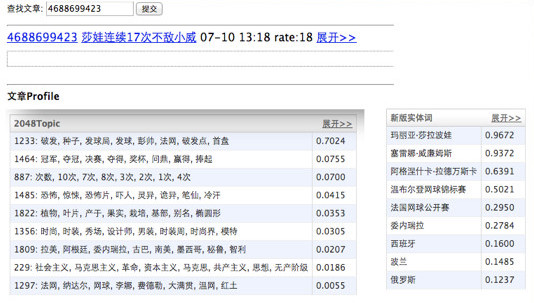
What are the article features?
-
Semantic Tags: Human predefine those tags with explicit meanings.
-
Implicit Semantics, including topics and keywords. Topic features are describing the statistics of words. Certain rules generate keywords.
-
Similarity. Duplicate recommendation once to be the most severe feedbacks we get from our customers.
-
Time and location.
-
Quality. Abusing, porn, ads, or “chicken soup for the soul”?
Article features are important
- It is not true that a recommendation system cannot work at all without article features. Amazon, Walmart, Netflix can recommend by collaborative filtering.
- However, in news product, users consume contents of the same day. Bootstrapping without article features is hard. Collaborative filtering cannot help with bootstrapping.
- The finer of the granularity of the article feature, the better the ability to bootstrap.
More on Semantic Tags
We divide features of semantic tags into three levels:
- Categorizations: used in the user profile, filtering contents in topics, recommend recall, recommend features
- Concepts: used in filtering contents in topics, searching tags, recommend recall(like)
- Entities: used in filtering contents in topics, searching tags, recommend recall(like)
Why dividing into different levels? We do this so that they can capture articles in different granularities.
- Categorizations: full in coverage, low in accuracy.
- Concepts: medium in coverage, medium in accuracy.
- Entities: low in coverage, high in accuracy. It only covers hot people, organizations, products in each area.
Categorizations and concepts are sharing the same technical infrastructure.
Why do we need semantic tags?
- Implicit semantics
- have been functioning well.
- cost much less than semantic tags.
- But, topics and interests need a clear-defined tagging system.
- Semantic tags also evaluate the capability in NPL technology of a company.
Document classification
Classification hierarchy
- Root
- Science, sports, finance, entertainment
- Football, tennis, table tennis, track and field, swimming
- International, domestic
- Team A, team B
Classifiers:
- SVM
- SVM + CNN
- SVM + CNN + RNN
Calculating relevance
- Lexical analysis for articles
- Filtering keywords
- Disambiguation
- Calculating relevance