Google Software Engineering: Software Development
It is widely recognized that Google is a company with exceptional engineering capabilities. What are its best engineering practices? What insights can we gain from them? What aspects have drawn criticism? We will discuss these details gradually, with this article primarily focusing on development.
Codebase
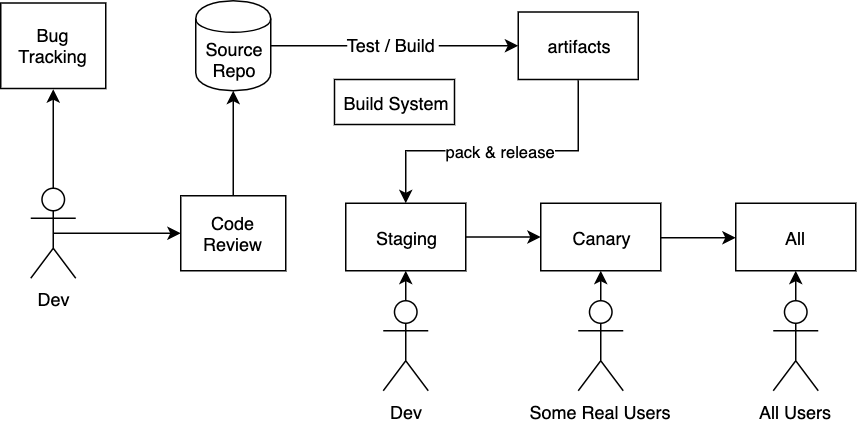
- As of 2015, there are 2 billion lines of code in a small number of Monorepo single codebases, with the vast majority of the code visible to everyone. Google encourages engineers to make changes when they see issues, as long as all reviewers approve, the changes can be integrated.
- Almost all development occurs at the head of the codebase, rather than on branches, to avoid issues during merging and to facilitate safe fixes.
- Every change triggers tests, and any errors are reported to the author and reviewers within minutes.
- Each subtree of the codebase has at least two owners; other developers can submit modifications, but approval from the owners is required for integration.
Build System
- The distributed build system Bazel makes compilation, linking, and testing easy and fast.
- Hundreds or thousands of machines are utilized.
- High reliability, with deterministic input dependencies leading to predictable output results, avoiding strange, uncertain fluctuations.
- Fast. Once a build result is cached, dependent builds will directly use the cache without needing to recompile. Only the changed parts are rebuilt.
- Pre-submit checks. Some quick tests can be executed before submission.
Code Review
- There are code review tools in place.
- All changes must undergo review.
- After discovering a bug, you can point out the issue in the previous review, and relevant personnel will be notified via email.
- Experimental code does not require mandatory review, but code in production must be reviewed.
- Each change is encouraged to be as small as possible. Fewer than 100 lines is "small," fewer than 300 lines is "medium," fewer than 1000 lines is "large," and more than 1000 lines is "extremely large."
Testing
- Unit tests
- Integration tests, regression tests
- Pre-submit checks
- Automatic generation of test coverage
- Conduct stress tests before deployment, generating relevant key metrics, especially latency and error rates as load varies.
Bug Tracking Tools
Bugs, feature requests, customer issues, processes, etc., are all recorded and need to be regularly triaged to confirm priorities and then assigned to the appropriate engineers.
Programming Languages
- There are five official languages: C++, Java, Python, Go, JavaScript, to facilitate code reuse and collaborative development. Each language has a style guide.
- Engineers undergo training in code readability.
- Domain-specific languages (DSLs) are also unavoidable in certain contexts.
- Data interaction between these languages primarily occurs through protocol buffers.
- A common workflow is essential, regardless of the language used.
Debugging and Analysis Tools
- When a server crashes, the crash information is automatically recorded.
- Memory leaks are accompanied by the current heap objects.
- There are numerous web tools to help you monitor RPC requests, change settings, resource consumption, etc.
Release
- Most release work is performed by regular engineers.
- Timely releases are crucial, as a fast release cadence greatly motivates engineers to work harder and receive feedback more quickly.
- A typical release process includes:
- Finding the latest stable build, creating a release branch, possibly cherry-picking some minor changes.
- Running tests, building, and packaging.
- Deploying to a staging server for internal testing, where you can shadow online traffic to check for issues.
- Releasing to a canary environment to handle a small amount of traffic for public testing.
- Gradually releasing to all users.
Review of Releases
User-visible or significant releases must undergo reviews related to legal, privacy, security, reliability, and business requirements, ensuring relevant personnel are notified. There are dedicated tools to assist with this process.
Postmortem Reports
After a significant outage incident, the responsible parties must write a postmortem report, which includes:
- Incident title
- Summary
- Impact: duration, affected traffic, and profit loss
- Timeline: documenting the occurrence, diagnosis, and resolution
- Root causes
- What went well and what did not: what lessons can help others find and resolve issues more quickly and accurately next time?
- Next actionable items: what can be done to prevent similar incidents in the future?
Focus on the issue, not the person; the key here is to understand the problem itself and how to avoid similar issues in the future.
Code Rewrite
Large software systems are often rewritten every few years. The downside is the high cost, but the benefits include:
- Maintaining agility. Markets change, software requirements evolve, and code must adapt accordingly.
- Reducing complexity.
- Transferring knowledge to newcomers, giving them a sense of ownership.
- Enhancing engineer mobility and promoting cross-domain innovation.
- Adopting the latest technology stacks and methodologies.
My Comments
Google's single codebase and powerful build system are not easily replicable by small companies, as they lack the resources and capabilities to make their build systems as fast and agile. Staying small, simple, and fast allows small companies to operate more smoothly and focus more on core business logic.
Build systems are often customized, and your knowledge may not transfer or scale. A powerful build system can even be detrimental to newcomers, as it raises the cost of gaining a holistic view.
The inability to transfer and scale knowledge is also an issue with well-developed in-house tools. Throughout my career, I have tried to avoid using non-open-source internal tools, such as Uber's Schemaless, which are tailored for specific scenarios and not made public for broader use; in contrast, LinkedIn's Kafka is a good product with openness and scalability of knowledge.
In the open market, there are excellent tools available for the entire development, testing, integration, and release process. For example, in the JS community:
| Process | Tools |
|---|---|
| Codebase | Github, Gitlab, Bitbucket, gitolite |
| Code Review | Github Pull Requests, Phabricator |
| Pre-submit checks, testing, and linting | husky, ava, istanbul, eslint, prettier |
| Bug Tracking | Github Issues, Phabricator |
| Testing and Continuous Integration | CircleCI, TravisCI, TeamCity |
| Deployment | Online service deployment with Heroku, Netlify, mobile app deployment with Fastlane, library publication with NPM |
Finally, I may have an insight: companies that do not focus on the automation of these engineering processes will lose significant competitive advantage. I even set up a JS full-stack development framework OneFx for good engineering practices. The difference between fast and slow, high quality and low quality is often exponential because — typically, speed allows you to do more and faster, while poor quality leads to less and worse outcomes.