Facebook如何存储大规模社交图谱(graph)?TAO
· 阅读需 2 分钟
挑战是什么?
在TAO之前,用 cache-aside pattern
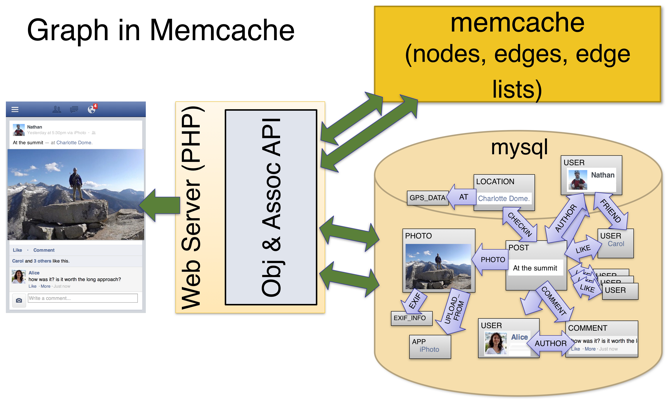
社交图谱是存储在MySQL和缓存在Memcached里的
3个存在的问题:
- 在Memcached中更新社交图谱的边列表操作效率太低。不是在列表的后面加一条边,而是要更新整个列表。
- 客户端管理缓存的逻辑很复杂
- 很难维持==数据库读在写之后这种一致性==
为了解决这些问题,我们有3个目标:
- 面对大规模数据仍然高效的图(graph)存储
- 优化读操作(读写比是500:1)
- 降低读操作的时长
- 提高读操作的可用性(最终一致性)
- 及时完成写操作 (先写再读)
数据模型
- 带 unique ID 的对象 (例如用户,地址,评论)
- 两个ID之间的关联 (例如被标记�,点赞,发表)
- 以上两个数据模型都有键值数据和时间相关数据
解决方案: TAO
-
加快读操作,高效处理大规模的读
-
及时完成写操作
- 透写缓存(write-through cache)
- 用follower/leader缓存去解决==惊群问题==
- 异步复制
-
提高读操作的可用性
- 如果读出错,则从其他可读的地方读
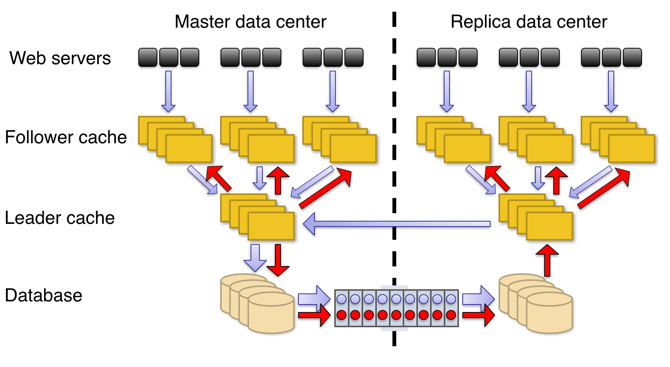
TAO 的架构
- MySQL数据库 → 持久性(durability)
- Leader缓存 → 协调每个对象的写操作
- Follower缓存 → 用来读而不是用来写。转移所有的写操作到leader缓存。
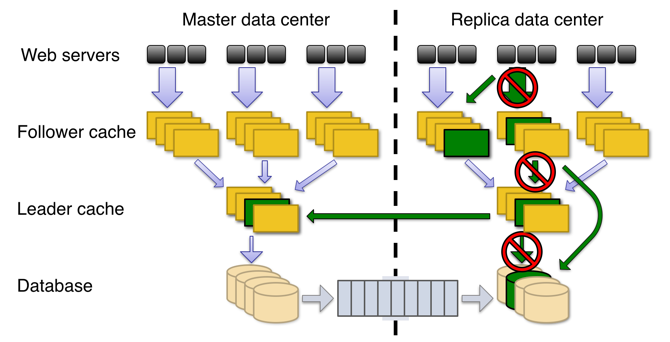
读操作的容错
- http://www.cs.cornell.edu/courses/cs6410/2015fa/slides/tao_atc.pptx
- https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf
- https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920/