Lambda Architecture
· 2 min read
Why Use Lambda Architecture?
To address the three issues brought by big data:
- Accuracy (good)
- Latency (fast)
- Throughput (high)
For example: The problems of scaling web browsing data records in a traditional way:
- First, use a traditional relational database.
- Then, add a "publish/subscribe" model queue.
- Next, scale through horizontal partitioning or sharding.
- Fault tolerance issues begin to arise.
- Data corruption phenomena start to appear.
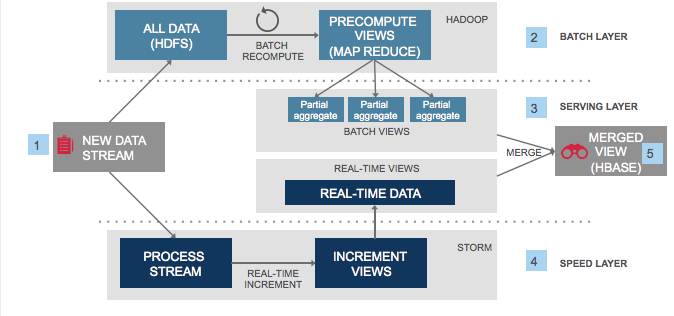
The key issue is that in the AKF Scaling Cube, ==having only the X-axis for horizontal partitioning of one dimension is not enough; we also need to introduce the Y-axis for functional decomposition. The lambda architecture can guide us on how to scale a data system==.
What is Lambda Architecture?
If we define a data system in the following form:
Query=function(all data)
Then a lambda architecture is:
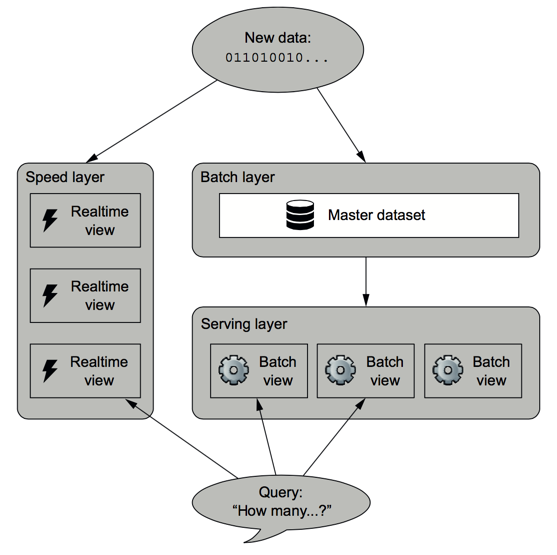
batch view = function(all data at the batching job's execution time)
realtime view = function(realtime view, new data)
query = function(batch view, realtime view)
==Lambda architecture = Read/Write separation (Batch Processing Layer + Service Layer) + Real-time Processing Layer==