设计实时联想搜索或自动完成功能
· 阅读需 2 分钟
需求
- 为社交网络(如 Linkedin 或 Facebook)提供实时 / 低延迟的联想和自动完成功能
- 使用前缀搜索社交资料
- 新添加的账户在搜索范围内即时出现
- 不是用于“查询自动完成”(如 Google 搜索框下拉),而是用于显示实际的搜索结果,包括
- 通用联想:来自全球排名方案(如人气)的网络无关结果。
- 网络联想:来自用户的第一和第二度网络连接的结果,以及“你可能认识的人”评分。
架构
多层架构
- 浏览器缓存
- 网络层
- 结果聚合器
- 各种联想后端
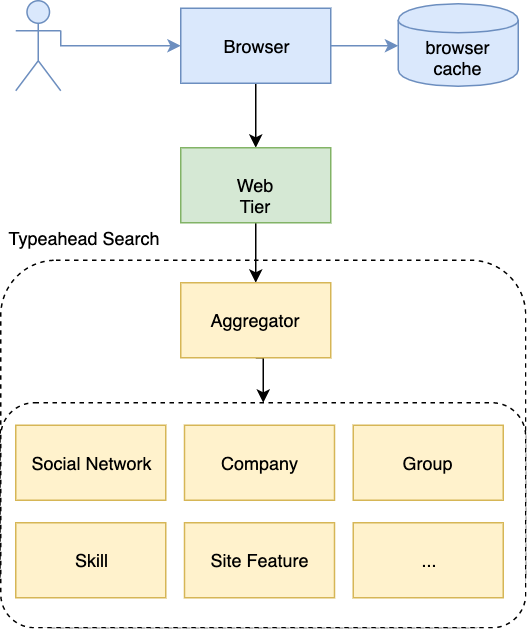
结果聚合器
这个问题的抽象是通过前缀和术语在大量元素中查找文档。解决方案利用这四种主要数据结构:
InvertedIndex<前缀或术语, 文档>:给定任何前缀,找到所有包含该前缀的文档 ID。为每个文档准备一个 BloomFilter<前缀或术语>:随着用户输入的增加,我们可以通过检查它们的布隆过滤器快速过滤掉不包含最新前缀或术语的文档。ForwardIndex<文档, 前缀或术语>:之前的布隆过滤器可能会返回假阳性,现在我们查询实际文档以拒绝它们。scorer(文档):相关性:每个分区返回所有真实命中及其评分。然后我们进行聚合和排名。
性能
- 通用联想:延迟 < = 1 毫秒在一个集群内
- 网络联想(第一和第二度网络的超大数据集):延迟 < = 15 毫秒
- 聚合器:延迟 < = 25 毫秒