Why Should We Care About Architecture?
The answer is: to reduce the human resources spent on each feature.
Mobile developers evaluate the quality of an architecture on three levels:
- Whether the responsibilities of different features are evenly distributed
- Whether it is easy to test
- Whether it is easy to use and maintain
| Responsibility Distribution | Testability | Usability |
|---|
| Tight Coupling MVC | ❌ | ❌ | ✅ |
| Cocoa MVC | ❌ V and C are coupled | ❌ | ✅⭐ |
| MVP | ✅ Independent view lifecycle | ✅ | Average: more code |
| MVVM | ✅ | Average: View has a dependency on UIKit | Average |
| VIPER | ✅⭐️ | ✅⭐️ | ❌ |
Tight Coupling MVC
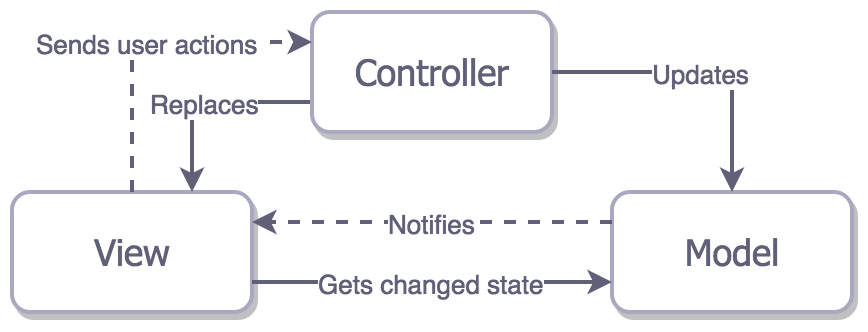
For example, in a multi-page web application, when you click a link to navigate to another page, the entire page reloads. The problem with this architecture is that the View is tightly coupled with the Controller and Model.
Cocoa MVC
Cocoa MVC is the architecture recommended by Apple for iOS developers. Theoretically, this architecture allows the Controller to decouple the Model from the View.
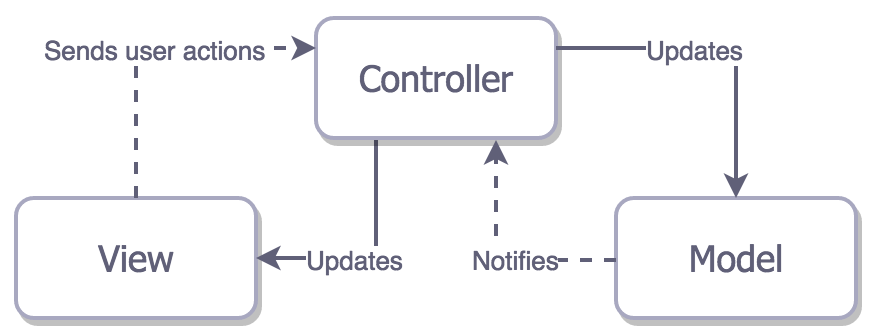
However, in practice, Cocoa MVC encourages the use of massive view controllers, ultimately leading to the view controller handling all operations.
Although testing such tightly coupled massive view controllers is quite difficult, Cocoa MVC performs the best in terms of development speed among the existing options.
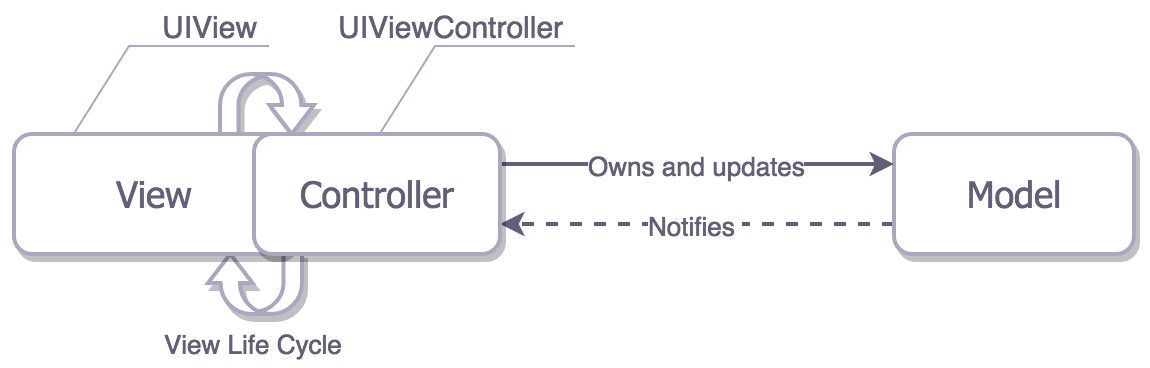
MVP
In MVP, the Presenter has no relationship with the lifecycle of the view controller, allowing the view to be easily replaced. We can think of UIViewController as the View.
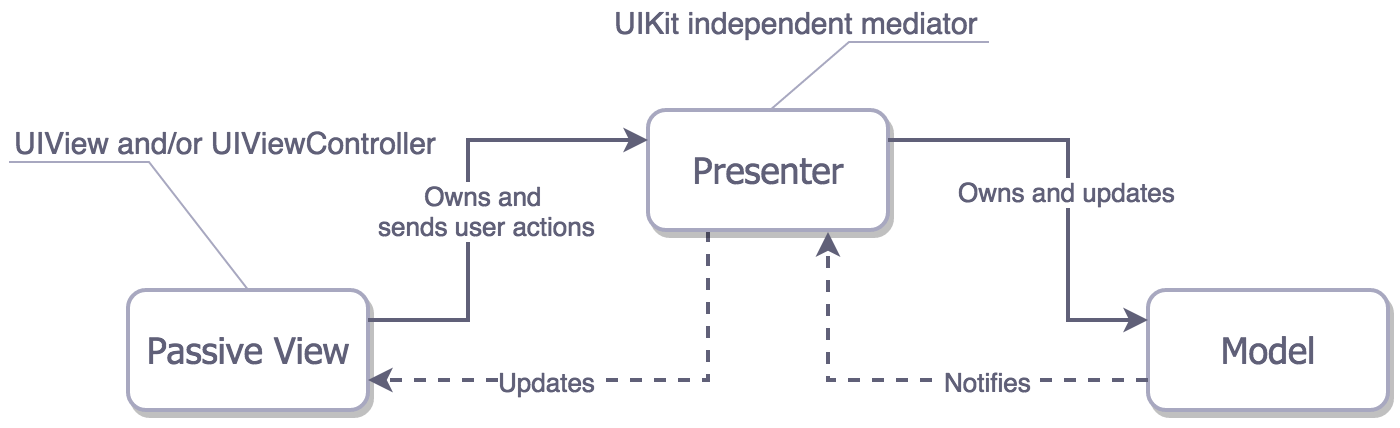
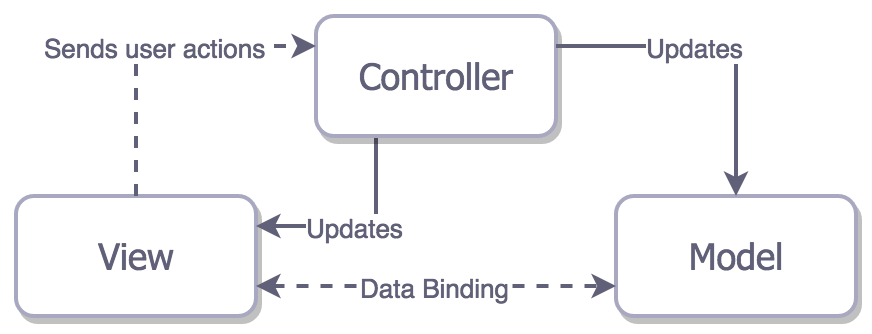
There is another type of MVP: MVP with data binding. As shown in the figure, the View is tightly coupled with the Model and Controller.
MVVM
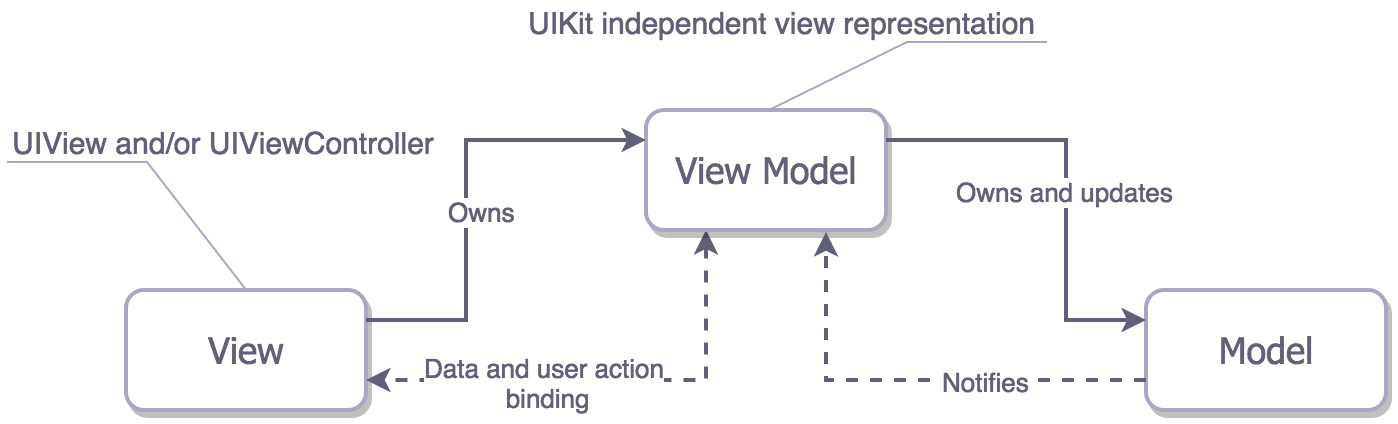
MVVM is similar to MVP, but MVVM binds the View to the View Model.
VIPER
Unlike the three-layer structure of MV(X), VIPER has a five-layer structure (VIPER View, Interactor, Presenter, Entity, and Routing). This structure allows for good responsibility distribution but has poorer maintainability.
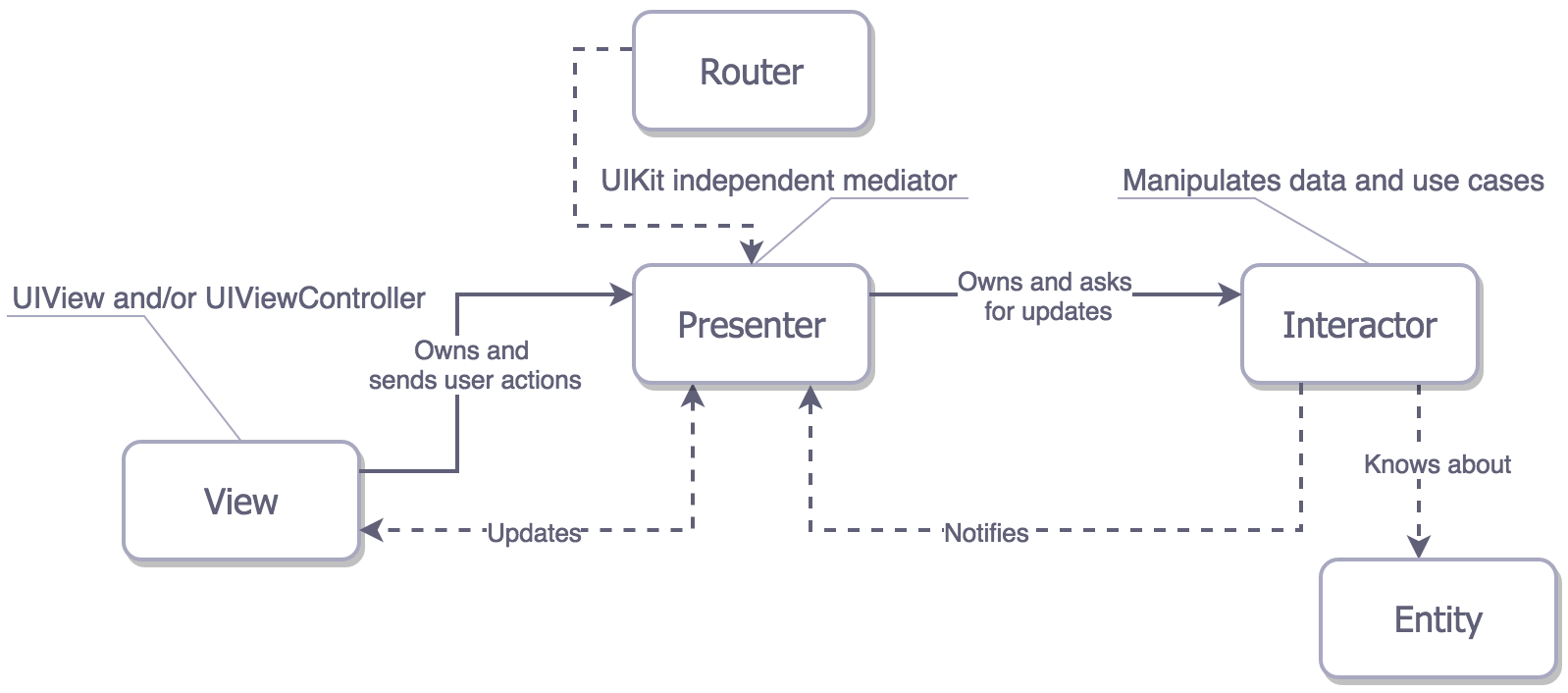
Compared to MV(X), VIPER has the following differences:
- The logic processing of the Model is transferred to the Interactor, so Entities have no logic and are purely data storage structures.
- ==UI-related business logic is handled in the Presenter, while data modification functions are handled in the Interactor==.
- VIPER introduces a routing module, Router, to implement inter-module navigation.
