什么是 Apache Kafka?
· 阅读需 4 分钟
Apache Kafka 是一个分布式流处理平台。
为什么使用 Apache Kafka?
它的抽象是一个 ==队列==,并且它具有
- 一个分布式的发布-订阅消息系统,将 N^2 关系解决为 N。发布者和订阅者可以以自己的速度操作。
- 采用零拷贝技术,速度极快
- 支持容错的数据持久性
它可以应用于
- 按主题进行日志记录
- 消息系统
- 地理复制
- 流处理
为什么 Kafka 这么快?
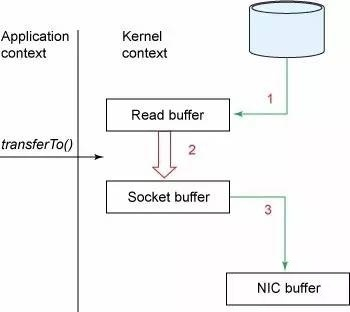
Kafka 使用零拷贝,CPU 不需要将数据从一个内存区域复制到另一个内存区域。
没有零拷贝的情况下:
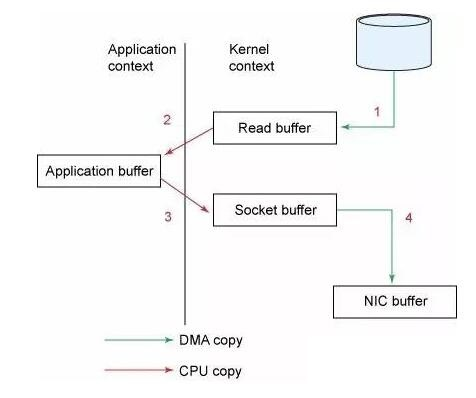
使用零拷贝的情况下:
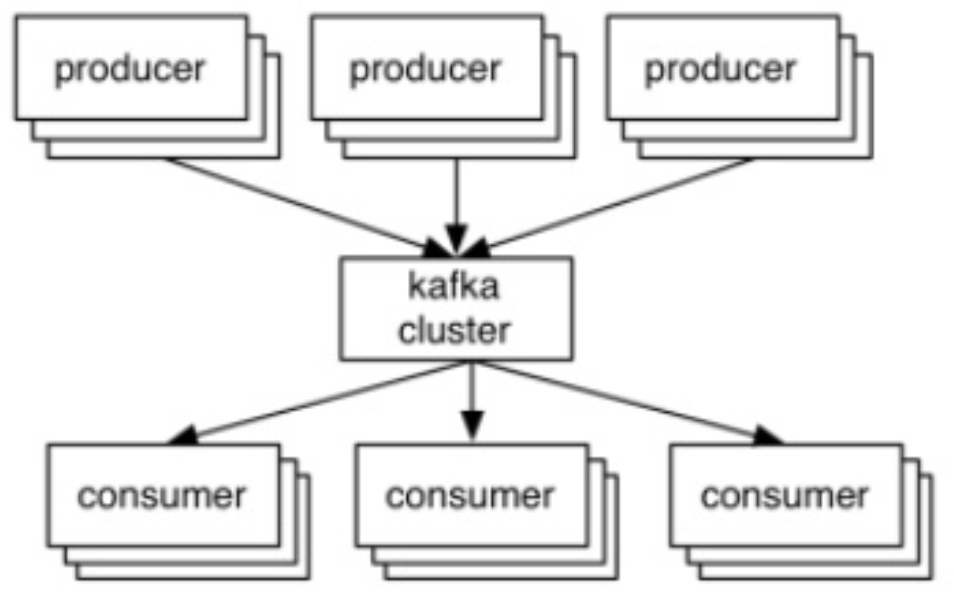
架构
从外部看,生产者写入代理,消费者从代理读取。
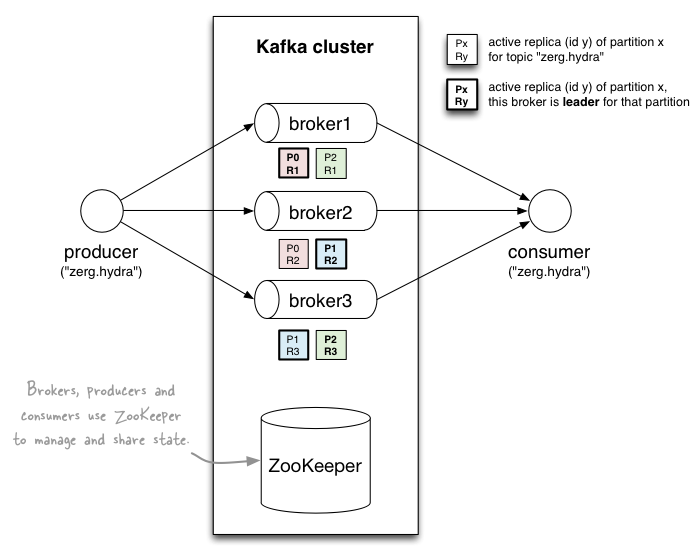
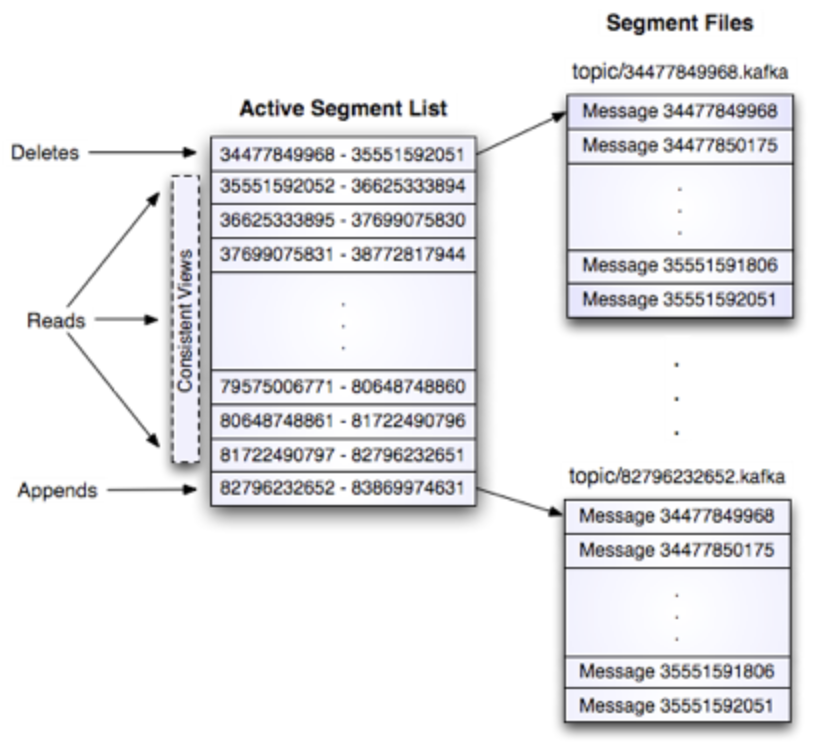
数据存储在主题中,并分割成多个分区,这些分区是复制的。
- 生产者将消息发布到特定主题。
- 首先写入内存缓冲区,然后刷新到磁盘。
- 仅追加的顺序写入以实现快速写入。
- 写入磁盘后可供读取。
- 消费者从特定主题中拉取消息。
- 使用“偏移指针”(偏移量作为 seqId)来跟踪/控制其唯一的读取进度。
- 一个主题由分区组成,负载均衡,分区(= 有序 + 不可变的消息序列,持续追加)
- 分区决定最大消费者(组)并行性。一个消费者在同一时间只能从一个分区读取。
如何序列化数据?Avro
它的网络协议是什么?TCP
分区的存储布局是什么?O(1) 磁盘读取
如何容错?
==同步副本 (ISR) 协议==。它容忍 (numReplicas - 1) 个死掉的代理。每个分区有一个领导者和一个或多个跟随者。
总副本 = ISRs + 不同步副本
- ISR 是活着的副本集合,并且已经完全追赶上领导者(注意领导者始终在 ISR 中)。
- 当发布新消息时,领导者会等待直到它到达 ISR 中的所有副本,然后才提交消息。
- ==如果一个跟随者副本失败,它将被移出 ISR,领导者随后继续以更少的副本在 ISR 中提交新消息。注意,现在系统正在以不足副本模式运行。== 如果领导者失败,将选择一个 ISR 成为新的领导者。
- 不同步副本继续从领导者拉取消息。一旦追赶上领导者,它将被重新添加到 ISR 中。
Kafka 是 CAP 定理 中的 AP 还是 CP 系统?
Jun Rao 说它是 CA,因为“我们的目标是在单个数据中心内支持 Kafka 集群的复制,在那里网络分区是罕见的,因此我们的设计专注于保持高度可用和强一致性的副本。”
然而,这实际上取决于配置。
-
默认配置(min.insync.replicas=1,default.replication.factor=1)开箱即用时,您将获得 AP 系统(至多一次)。
-
如果您想实现 CP,您可以将 min.insync.replicas 设置为 2,主题复制因子设置为 3 - 然后使用 acks=all 生产消息将保证 CP 设置(至少一次),但(如预期)在特定主题/分区对可用副本不足(<2)时将会阻塞。