Replica, Consistency, and CAP theorem
Why replica and consistency?
large dataset ⟶ scale out ⟶ data shard / partition ⟶ 1) routing for data access 2) replica for availability ⟶ consistency challenge
Consistency trade-offs for CAP theorem
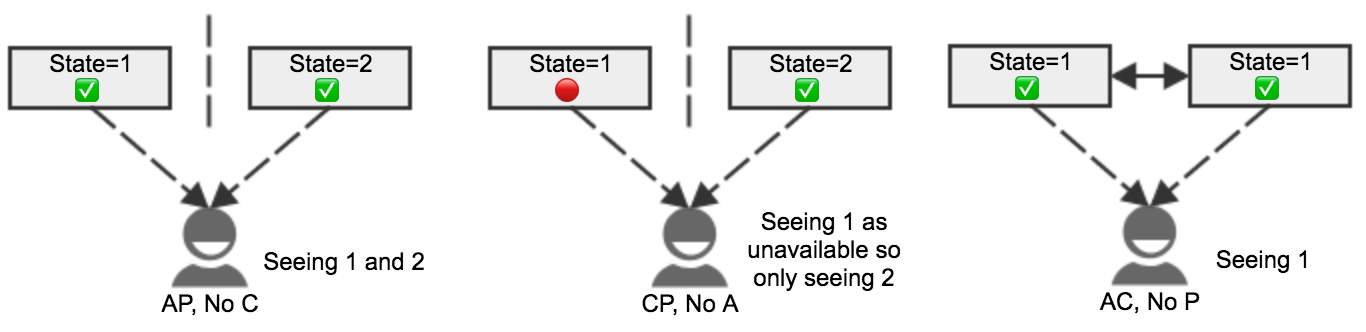
- Consistency: all nodes see the same data at the same time
- Availability: a guarantee that every request receives a response about whether it succeeded or failed
- Partition tolerance: system continues to operate despite arbitrary message loss or failure of part of the system
Any networked shared-data system can have only two of three desirable properties.
- rDBMS prefer CP ⟶ ACID
- NoSQL prefer AP ⟶ BASE
"2 of 3" is mis-leading
12 years later, the author Eric Brewer said "2 of 3" is mis-leading, because
- partitions are rare, there is little reason to forfeit C or A when the system is not partitioned.
- choices can be actually applied to multiple places within the same system at very fine granularity.
- choices are not binary but with certain degrees.
Consequently, when there is no partition (nodes are connected correctly), which is often the case, we should have both AC. When there are partitions, deal them with 3 steps:
- detect the start of a partition,
- enter an explicit partition mode that may limit some operations, and
- initiate partition recovery (compensate for mistakes) when communication is restored.