Design a system that can convert URLs provided by users into short URLs, allowing users to access their original URLs (hereinafter referred to as long URLs) using these short URLs. Describe how this system operates, including but not limited to the following questions: How are short URLs allocated? How is the mapping between short URLs and long URLs stored? How is the redirection service implemented? How is access data stored?
Assumptions: The initial problem description does not include these assumptions. An excellent candidate will ask about system scale when given a specific design.
- There are approximately tens of thousands of long URL domains.
- The traffic for new long URLs is about 10,000,000 per day (100 per second).
- The traffic for the redirection service using short URLs to access long URLs is about 10 billion per day (100,000 per second).
- Remind the candidate that these are average figures - during peak times, these numbers can be much higher (one type of peak time is time-related, such as when users return home from work, and another type is event-related, such as during the Spring Festival Gala).
- Recent data (e.g., today's data) should be collected in advance and should be available within five minutes when users want to view it.
- Historical data should be calculated daily.
Assumptions
1 billion new URLs per day, 100 billion short URL accesses.
The shorter the short URL, the better.
Data presentation (real-time/daily/monthly/yearly).
URL Encoding
http://blog.codinghorror.com/url-shortening-hashes-in-practice/
Method 1: md5 (128 bits, 16 hexadecimal digits, collisions, birthday paradox, 2^(n/2) = 2^64) Shorter? (64 bits, 8 hexadecimal digits, collisions 2^32), base 64.
- Advantages: Hashing is relatively simple and easy to scale horizontally.
- Disadvantages: Too long, how to handle expired URLs?
Method 2: Distributed ID generator. (Base 62: az, AZ, 0~9, 62 characters, 62^7), partitioning: each node contains some IDs.
- Advantages: Easier to eliminate expired URLs, shorter URLs.
- Disadvantages: Coordination between different partitions (e.g., ZooKeeper).
Key-Value (KV) Storage
MySQL (10k requests per second, slow, no need for a relational database), key-value (100k requests per second, Redis, Memcached).
An excellent candidate will ask about the expected lifespan of short URLs and design a system that can automatically clean up expired short URLs.
Follow-Up
Question: How to generate short URLs?
- A poor candidate might suggest using a single ID generator (single point of failure) or require coordination between ID generators for each ID generation. For example, using an auto-increment primary key in a database.
- An acceptable candidate might suggest using md5 or some UUID generators that can generate IDs independently on some nodes. These methods can generate non-colliding IDs in a distributed system, allowing for the production of a large number of short URLs.
- An excellent candidate will design a method using several ID generators, where each generator first reserves a block of ID sequences from a central coordinator (e.g., ZooKeeper), and these ID generators can allocate IDs from their ID sequences independently, cleaning up their ID sequences when necessary.
Question: How to store the mapping between long URLs and short URLs?
- A poor candidate might suggest using a single, non-distributed, non-relational database. It is merely a simple key-value database.
- An excellent candidate will suggest using a simple distributed storage system, such as MongoDB/HBase/Voldemort, etc.
- A more excellent candidate will ask about the expected usage cycle of short URLs and then design a system that can clean up expired short URLs.
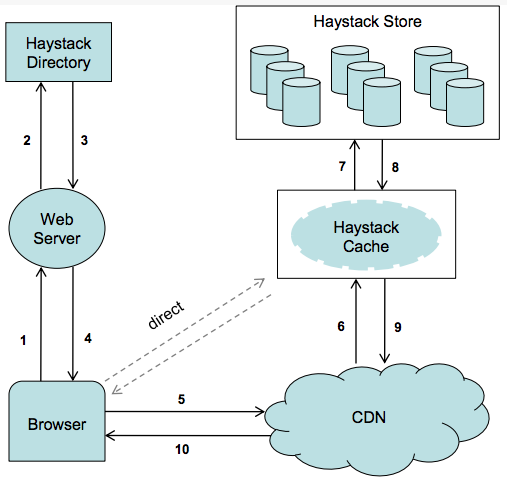
Question: How to implement the redirection service?
- A poor candidate will design the system from scratch to solve problems that have already been solved.
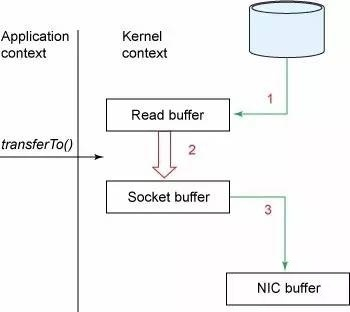
- An excellent candidate will suggest using an existing HTTP server with a plugin to translate the short URL ID, look up this ID in the database, update access data, return a 303 status, and redirect to the long URL. Existing HTTP servers include Apache/Jetty/Netty/Tomcat, etc.
Question: How to store access data?
- A poor candidate will suggest writing to the database on every access.
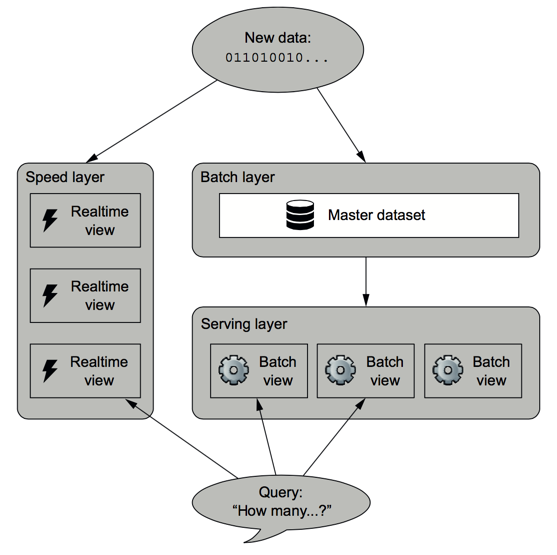
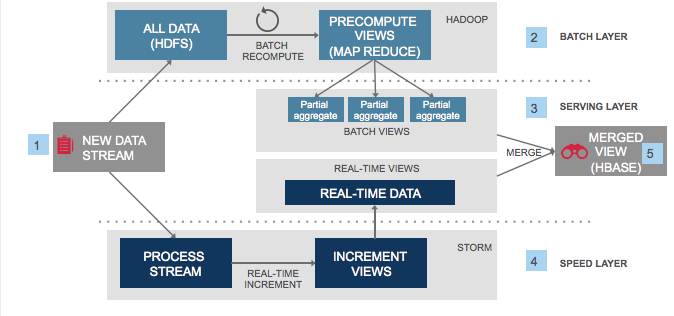
- An excellent candidate will suggest having several different components handle this task: generating access stream data, collecting and organizing it, and writing it to a permanent database after a certain period.
Question: How to separate the different components of storing access data proposed by the excellent candidate?
- An excellent candidate will suggest using a low-latency information system to temporarily store access data and then hand the data over to the collection and organization component.
- The candidate may ask how often access data needs to be updated. If updated daily, a reasonable method would be to store it in HDFS and use MapReduce to compute the data. If near-real-time data is required, the collection and organization component must compute the necessary data.
Question: How to block access to restricted websites?
- An excellent candidate will suggest maintaining a blacklist of domains in the key-value database.
- A good candidate might propose some advanced technologies that can be used when the system scales significantly, such as bloom filters.