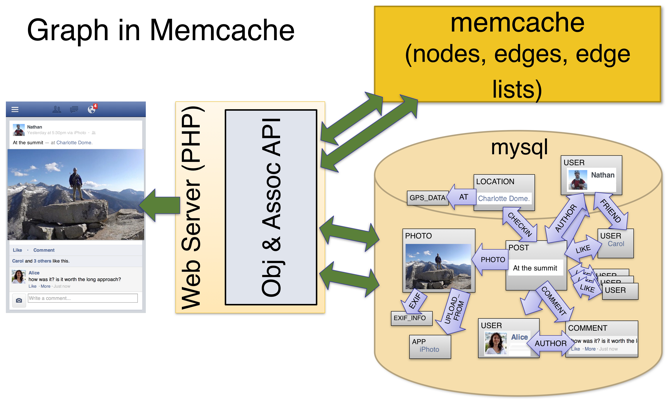
设计Facebook图片存储系统
· 阅读需 2 分钟
为什么 Facebook 要自己做图片存储?
- PB级别的Blob数据量
- 传统的基于NFS的设计(每个图像存储为文件)都存在元数据瓶颈:庞大的元数据严重限制了元数据命中率。
- 以下是细节解释:
对于图片应用程序,图片的权限等大多数元数据是无用的,从而浪费了存储空间。然而,更大的开销在于,必须将文件的元数据从磁盘读入内存中才能找到文件本身。虽然对于小规模存储来说这微不足道,但当乘以数十亿的照片和数PB的数据时,那么访问元数据将是吞吐量的瓶颈。
解决方案
通过把数以十万计的图像聚集到单个Haystack存储文件中,从而消除了元数据负荷。
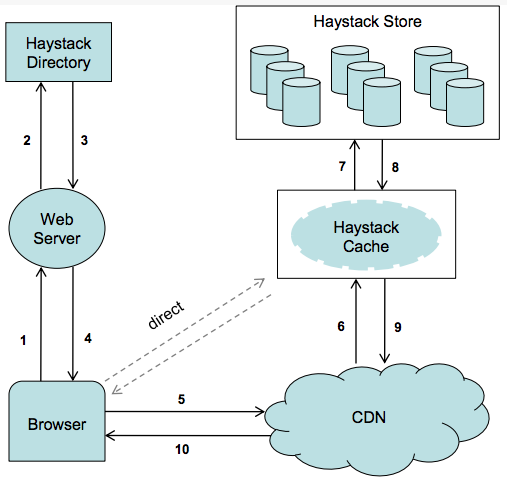
结构
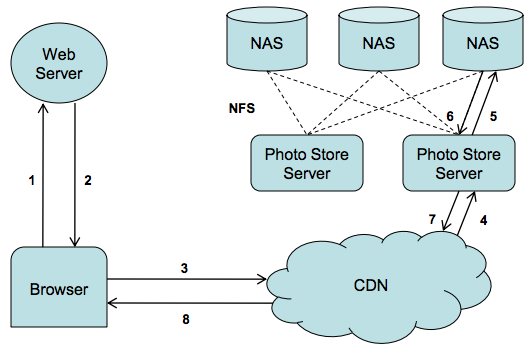
数据布局
索引文件(用于快速加载内存)+ 包含很多图片的haystack存储文件。
索引文件布局
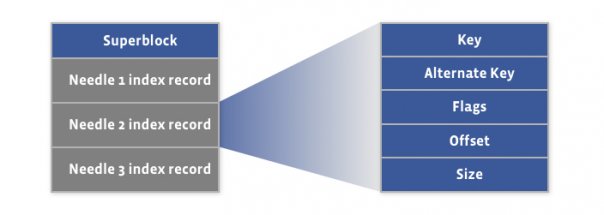
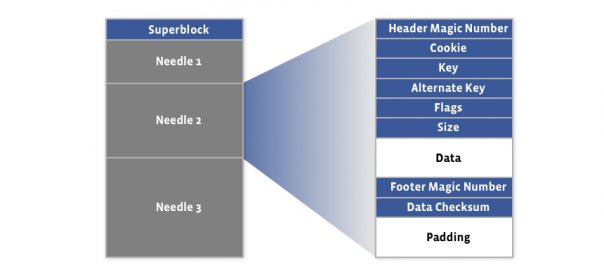
储存文件
CRUD操作
- 增: 写入存储文件,然后==异步==写入索引文件,因为建立索引并不是关键的步骤。
- 删: 通过在标志字段中标记已删除的位来进行软删除。通过紧凑操作执行硬删除。
- 改: 在更新时,只能追加 (append-only),如果遇到了重复的键,应用程序可以选择具有最大偏移量的键去改和读。
- 查: 读取操作(偏移量,健,备用键,Cookie 以及数据大小)
用例
上传
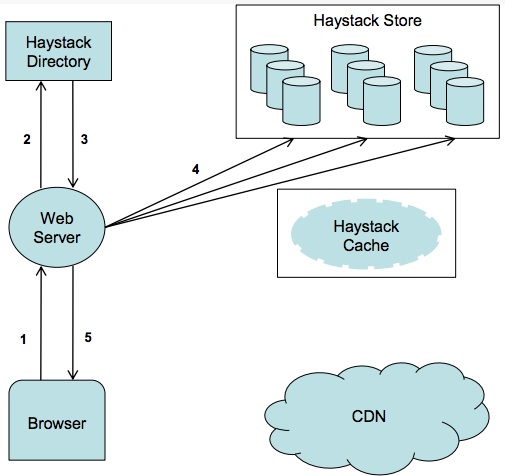
下载