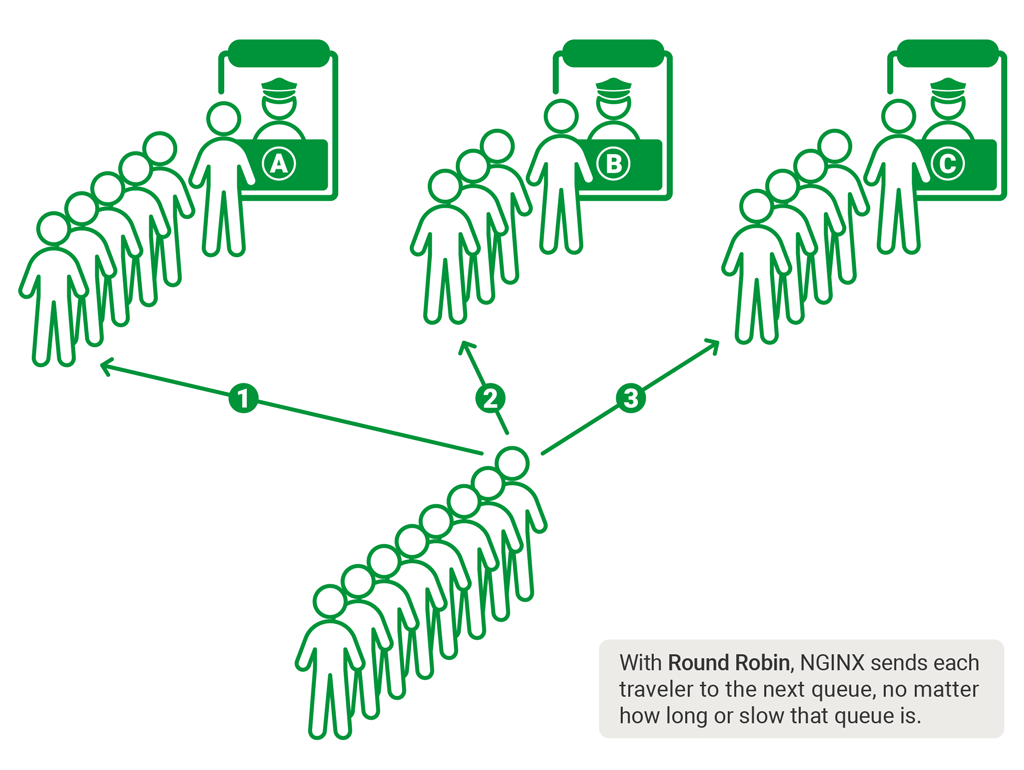
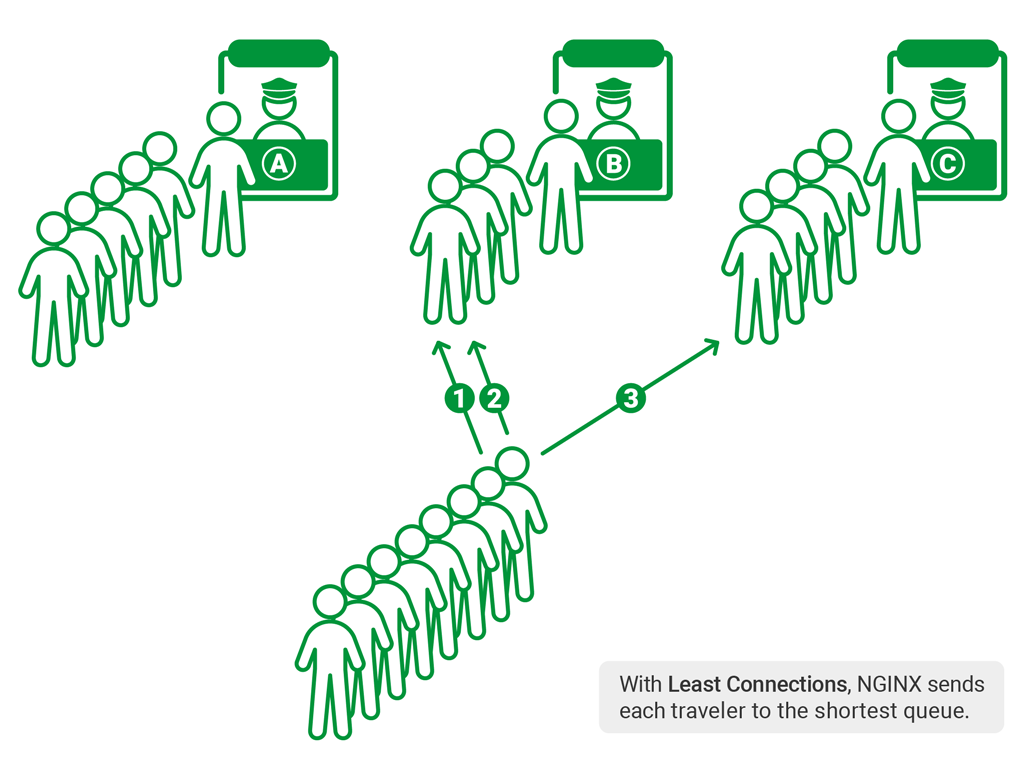
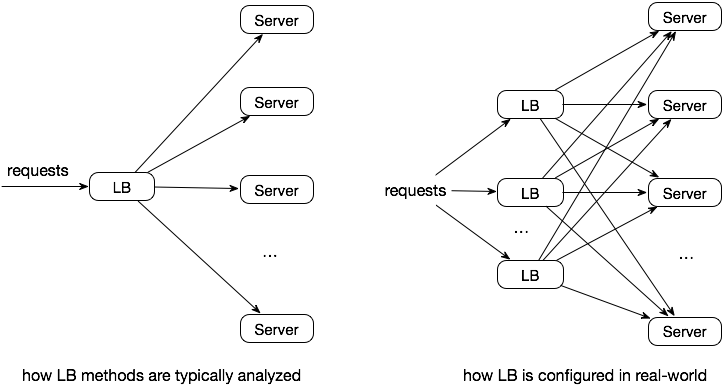
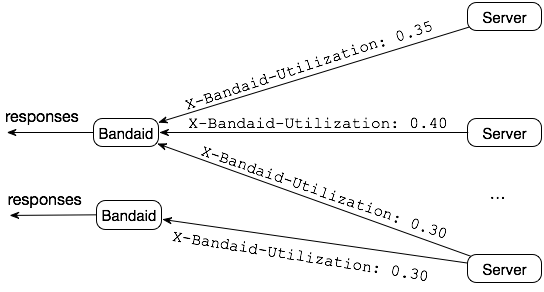
- 设计一个从简单开始但可以随着业务扩展的身份验证解决方案
- 考虑安全性和用户体验
- 讨论该领域的未来趋势
大局观:身份验证(AuthN)、授权(AuthZ)和身份管理
首先,回归基础
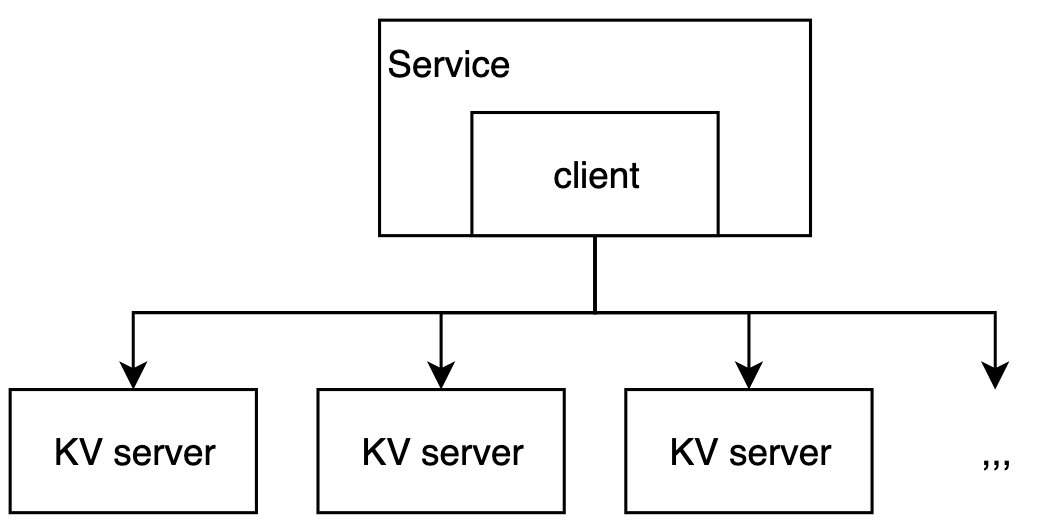
在开始时……让我们有一个简单的服务……
然后,随着业务的增长,我们用AKF规模立方体来扩展系统:
加上康威定律:组织设计的系统反映其沟通结构。我们通常将架构演变为微服务(参见为什么选择微服务?了解更多)
- 顺便说一句,“微服务与单体”和“多仓库与单仓库”是不同的概念。
- 对于企业,有员工身份验证和客户身份验证。我们更关注客户身份验证。
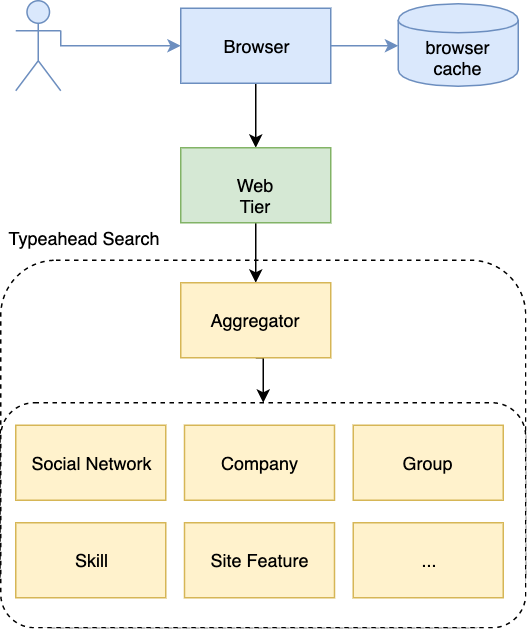
在微服务世界中,让我们抽取身份验证和授权服务的功能切片,并有一个身份和访问管理(IAM)团队在进行相关工作。
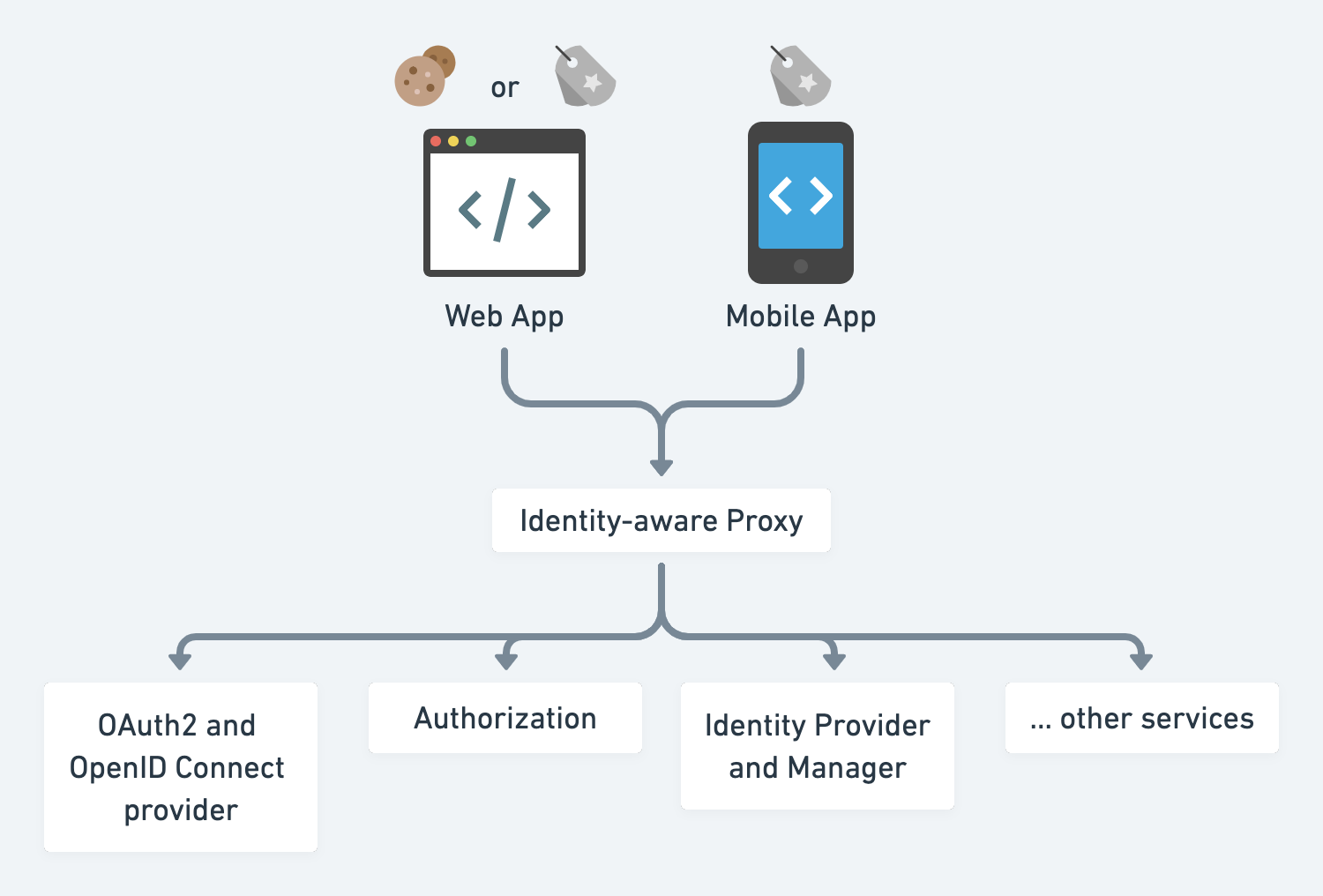
身份验证
身份提供者
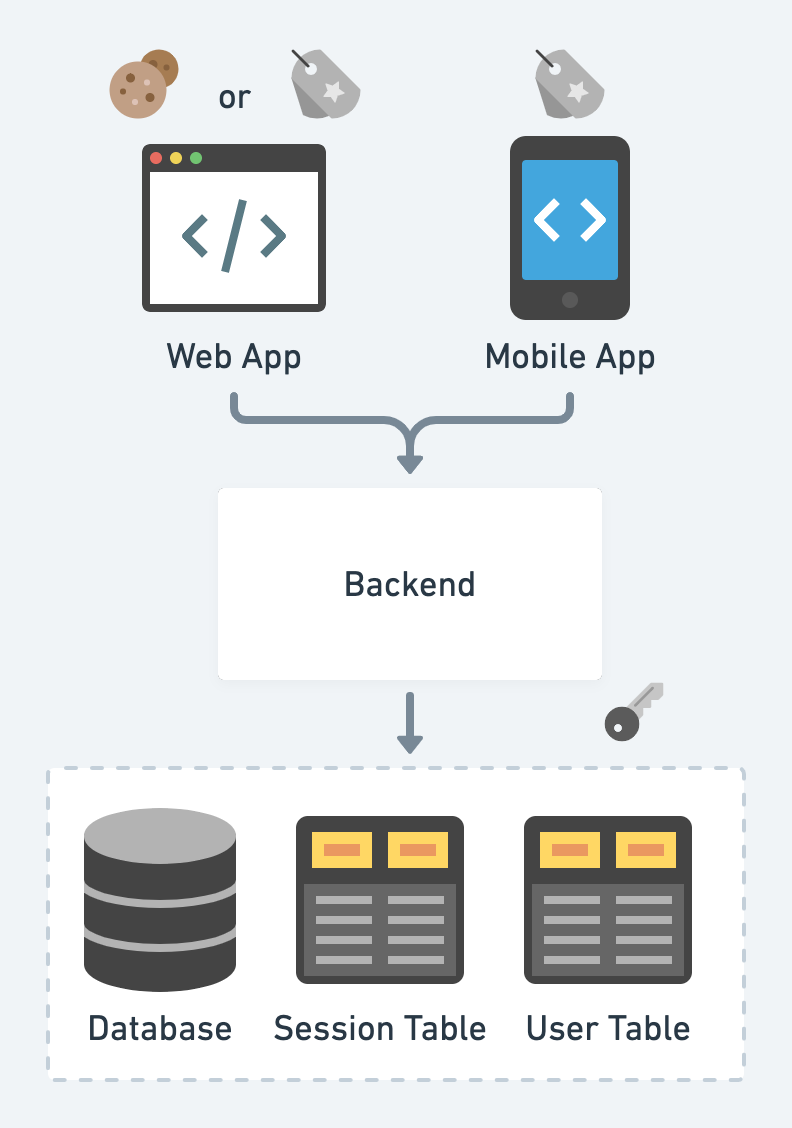
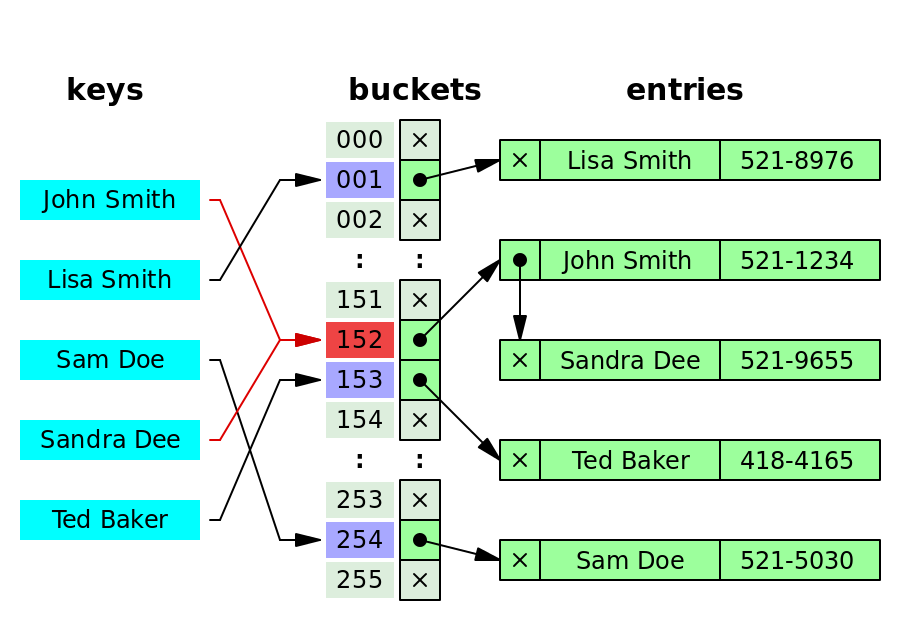
- 最简单的解决方案是提交用户的身份证明并发放服务凭证。
- 然而,现代应用程序通常处理复杂的工作流,如条件注册、多步骤登录、忘记密码等。
这些工作流本质上是状态机中的状态转换图。
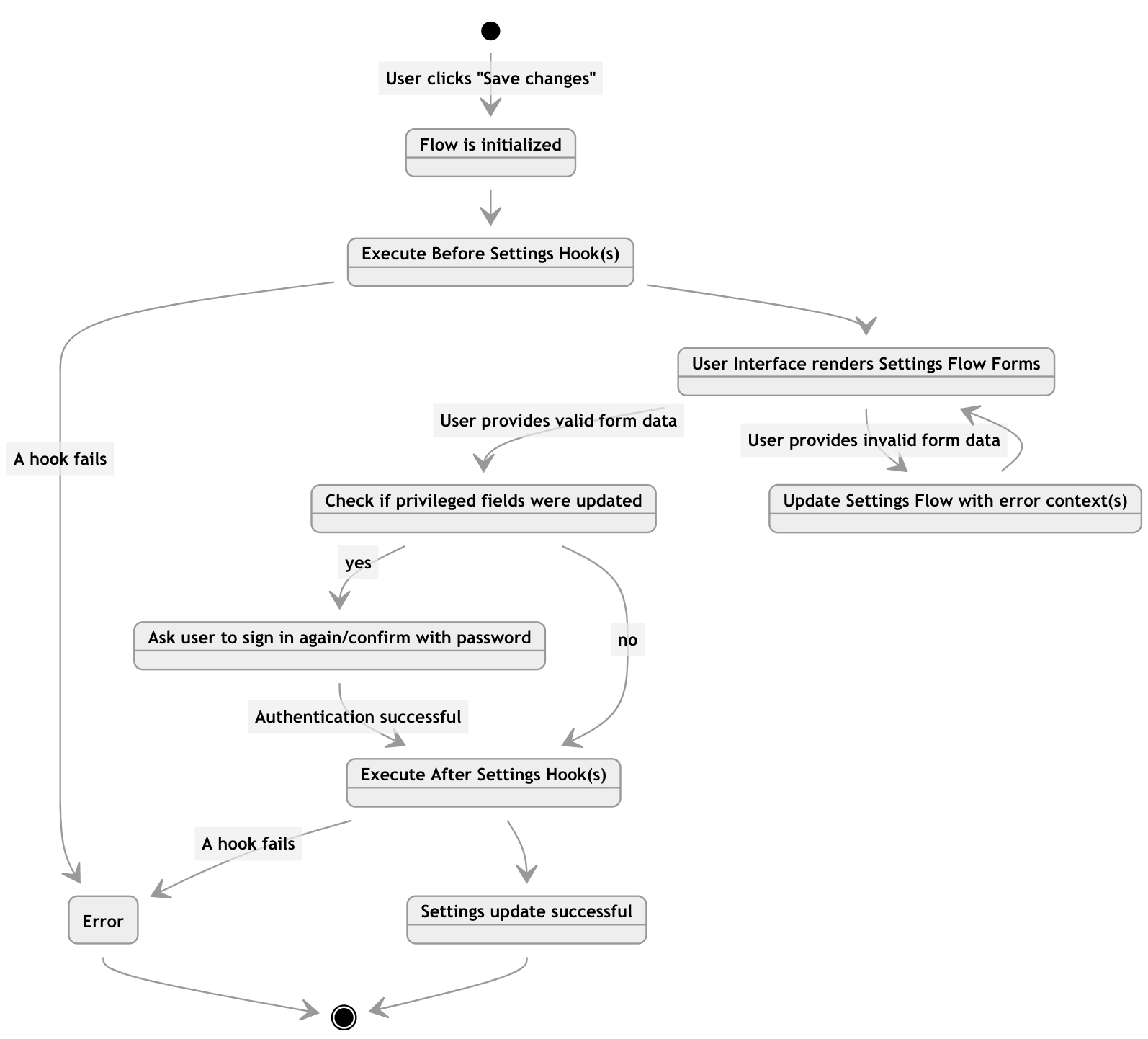
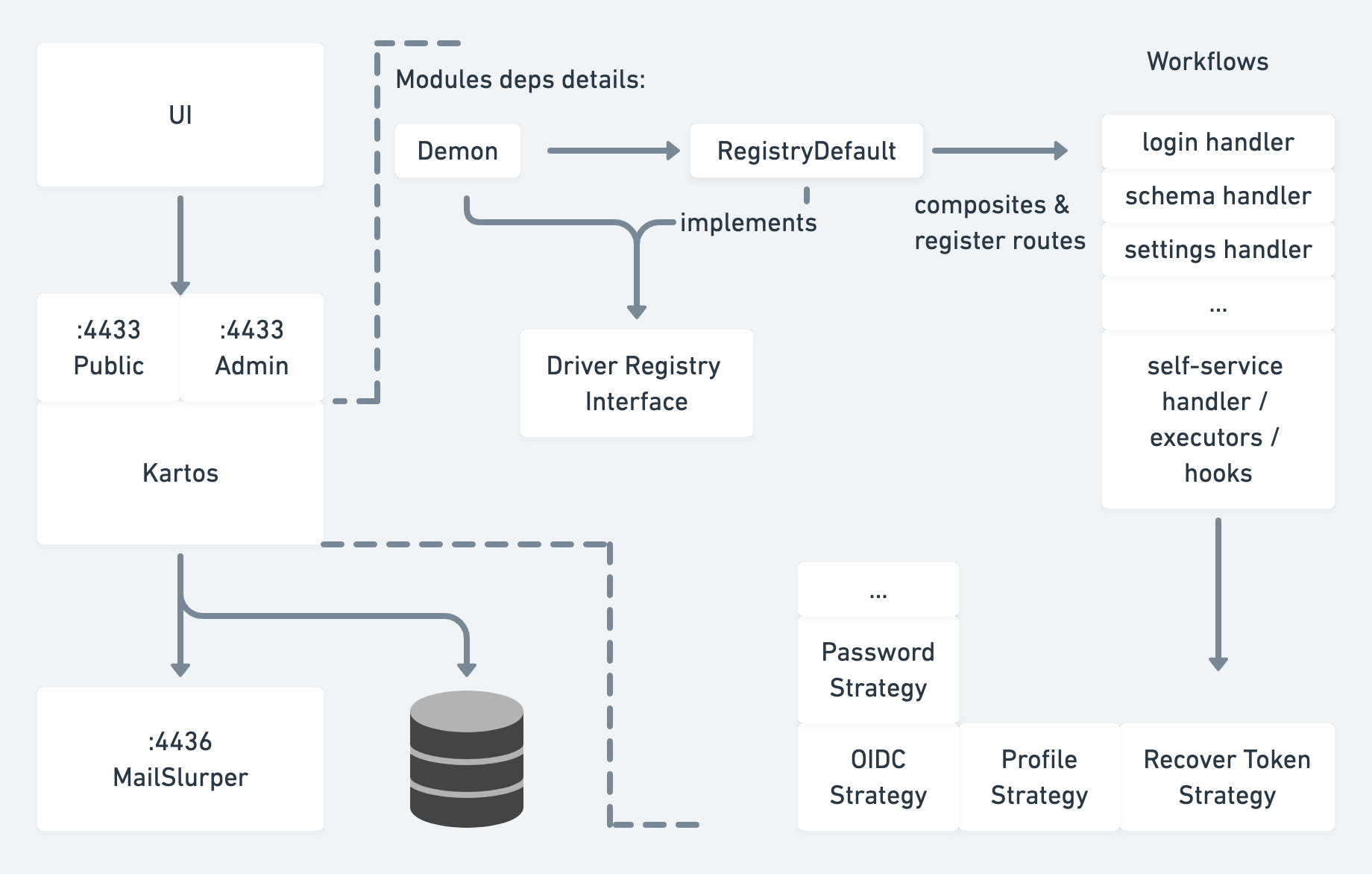
工作流:用户设置和个人资料更新
Ory.sh/Kratos作为示例架构
2. 第三方OAuth2
OAuth2让用户或客户端经历四个主要工作流(不确定使用哪个?请查看这个),如
- Web的授权码授权
- 移动的隐式授权
- 传统应用的资源拥有者密码凭证授权
- 后端应用流的客户端凭证授权
然后最终获得访问令牌和刷新令牌
- 访问令牌是短期有效的,因此如果被泄�露,攻击窗口很短
- 刷新令牌仅在与客户端ID和密钥结合使用时有效
假设在这个工作流中涉及许多实体 - 客户端、资源拥有者、授权服务器、资源服务器、网络等。更多的实体会增加被攻击的暴露。一个全面的协议应该考虑所有边缘情况。例如,如果网络不是HTTPs /不能完全信任怎么办?
OpenID Connect是基于OAuth2的身份协议,它定义了可定制的RESTful API,供产品实现单点登录(SSO)。
在这些工作流和令牌处理过程中有很多棘手的细节。不要重新发明轮子。
3. 多因素身份验证
问题:凭证填充攻击
用户倾向于在多个网站上重复使用相同的用户名和密码。当其中一个网站遭遇数据泄露时,黑客会使用这些泄露的凭证对其他网站进行暴力攻击。
- 多因素身份验证:短信、电子邮件、电话语音一次性密码、身份验证器一次性密码
- 速率限制器、失败禁止和异常检测
挑战:电子邮件或短信的送达率差
- 不要将营销电子邮件渠道与事务性渠道共享。
- 语音一次性密码通常具有更好的送达率。
5. 无密码
- 生物识别:指纹、面部识别、声音识别
- 二维码
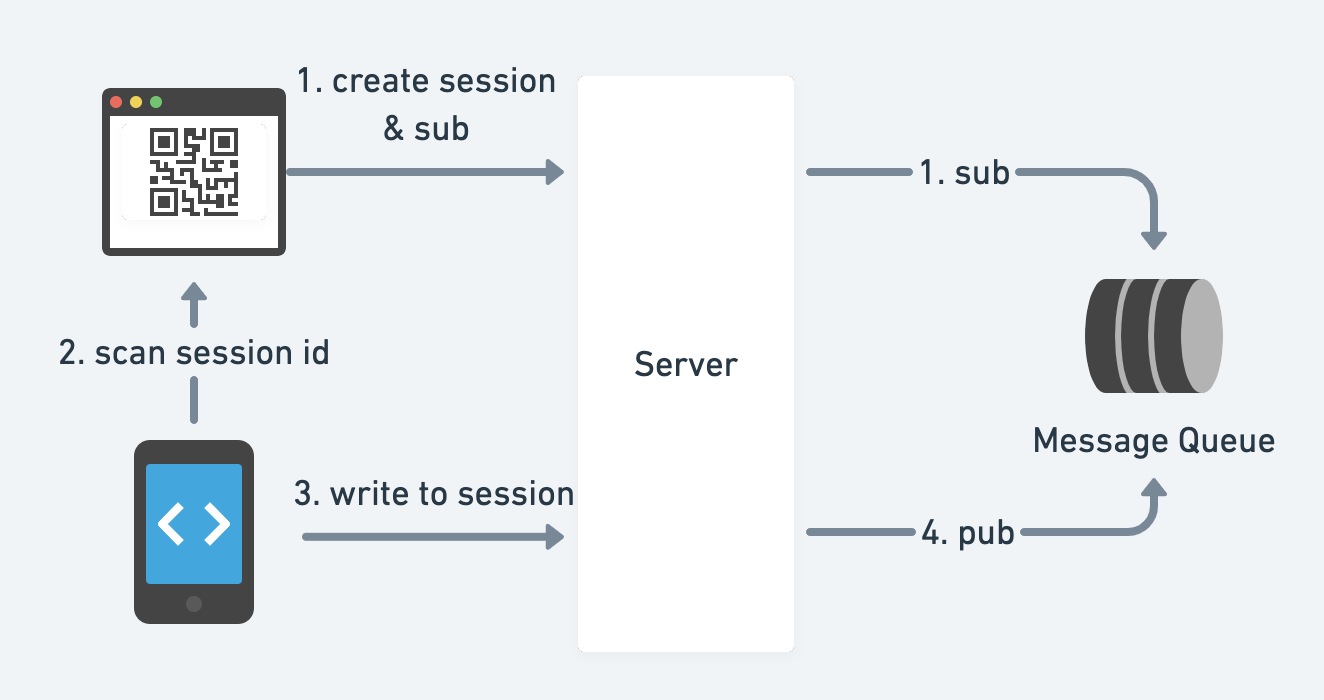
- 推送通知
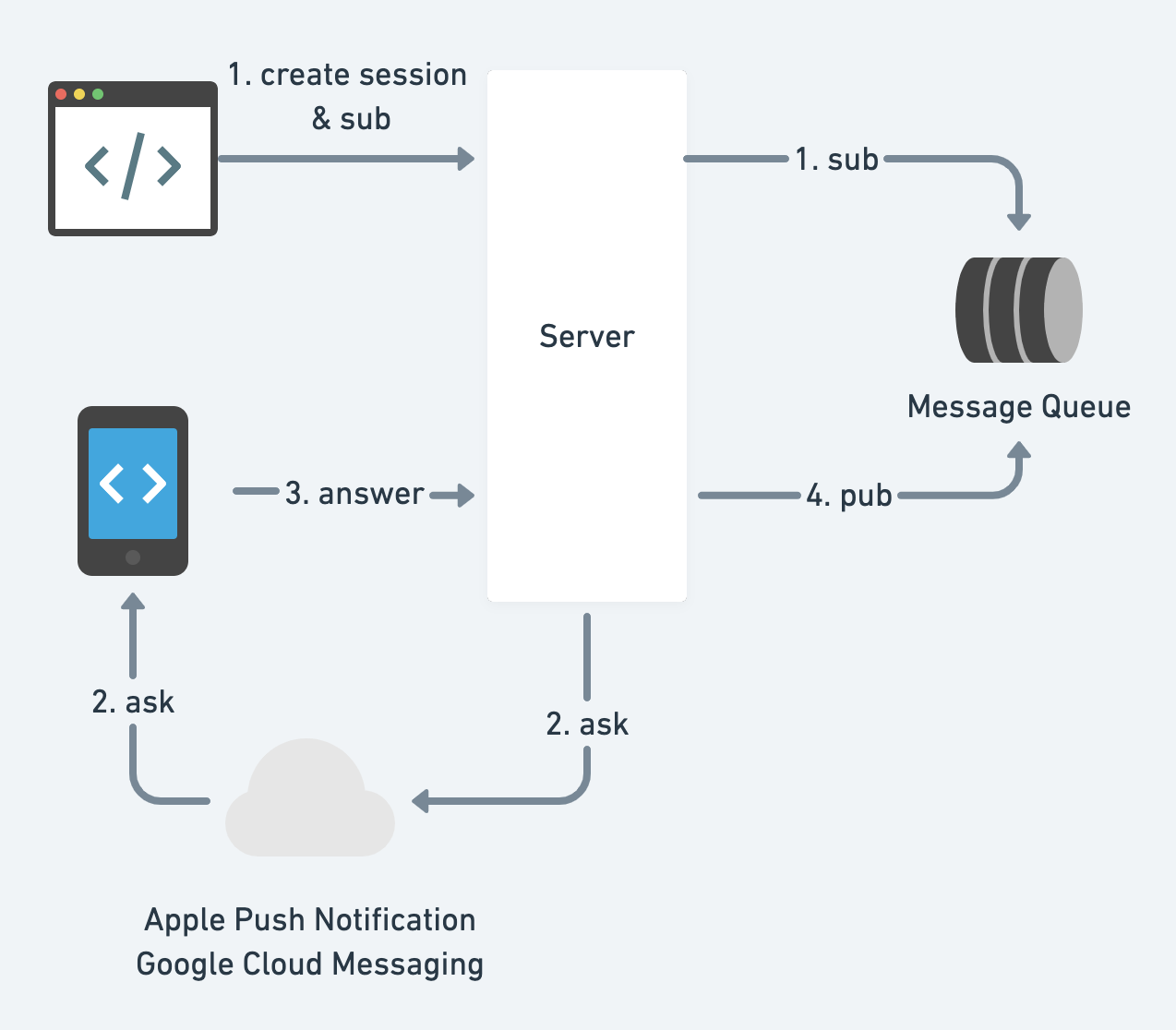
客户端如何订阅服务器的状态?短轮询、长轮询、WebSocket或服务器推送事件。
4. 市场上的供应商
不要重新发明轮子。
6. 优化
挑战1:Web登录非常慢或根本无法提交登录表单。
- JS包对于移动Web来说太大
- 构建一个轻量级的PWA版本的SPA(单页面Web应用)。无论如何使包小 - 例如,preact或inferno
- 或者根本不使用SPA��。简单的MPA(多页面Web应用)与原始HTML表单提交效果很好
- 浏览器兼容性
- 使用BrowserStack或其他工具在不同浏览器上进行测试
- 数据中心距离太远
- 将静态资源放到边缘/CDN,并通过Google骨干网中继API请求
- 建立一个本地数据中心 😄
请参见Web应用交付优化以获取更多信息
挑战2:账户接管
挑战3:账户创建耗时过长
当后端系统变得过于庞大时,用户创建可能会分散到许多服务,并在不同数据源中创建许多条目。在注册结束时等待15秒感觉很糟糕,对吧?
- 收集并逐步注册
- 异步
isAuthorized(subject, action, resource)
1. 基于角色的访问控制(RBAC)

2. 基于策略的访问控制(PBAC)
{
"subjects": ["alice"],
"resources": ["blog_posts:my-first-blog-post"],
"actions": ["delete"],
"effect": "allow"
}
挑战:单点故障和级联故障
- 预处理和缓存权限
- 利用请求上下文
- 假设:数据中心内部的请求是可信的,而外部请求则不可信
- 失败开放与失败关闭
1. 个人可识别信息(PII)、受保护的健康信息(PHI)、支付卡行业(PCI)
西方文化有尊重隐私的传统,尤其是在纳粹杀害数百万人之后。
以下是一些典型的敏感数据类型:个人可识别信息(PII)、受保护的健康信息(PHI,受HIPAA监管)和信用卡或支付卡行业(PCI)信息。
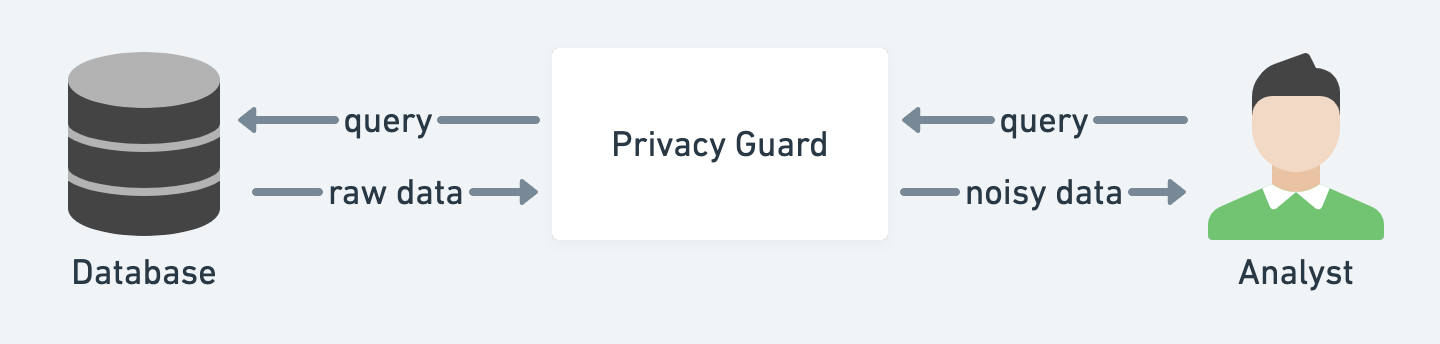
2. 差分隐私
仅仅删除敏感信息可能不足以防止与其他数据集相关的数据泄露。
差分隐私帮助分析师从包含个人信息的数据库中提取数据,但仍然保护个人隐私。
3. 去中心化身份
为了将身份与集中式身份提供者及其相关的敏感数据解耦,我们可以使用去中心化身份(DID)。
- 它本质上采用URN格式:
did:example:123456789abcdefghijk
- 它可以从非对称密钥及其目标业务领域派生。
- 与传统方式不同,它不涉及您的个人信息
- 请参见DID方法了解其如何与区块链一起工作。
- 它通过以下方式保护隐私
- 为不同目的使用不同的DID
- 选择性披露/可验证声明
想象一下,艾丽斯有一个州政府颁发的DID,想在不透露真实姓名和确切年龄的情况下购买一些酒。

一个DID解决方案:
- 艾丽斯有一个身份档案,包含
did:ebfeb1f712ebc6f1c276e12ec21、姓名、头像URL、生日和其他敏感数据。
- 创建一个声明,表明
did:ebfeb1f712ebc6f1c276e12ec21超过21岁
- 一个受信任的第三方签署该声明,使其成为可验证声明
- 使用可验证声明作为年龄的证明
本文概述了微服务中的身份验证和授权,您不必记住所有内容才能成为专家。以下是一些要点:
- 遵循标准协议,不要重新发明轮子
- 不要低估安全研究人员/黑客的力量
- 完美是很难的,也不必完美。全面优先考虑您的开发工作
.png "Optimism 架构")