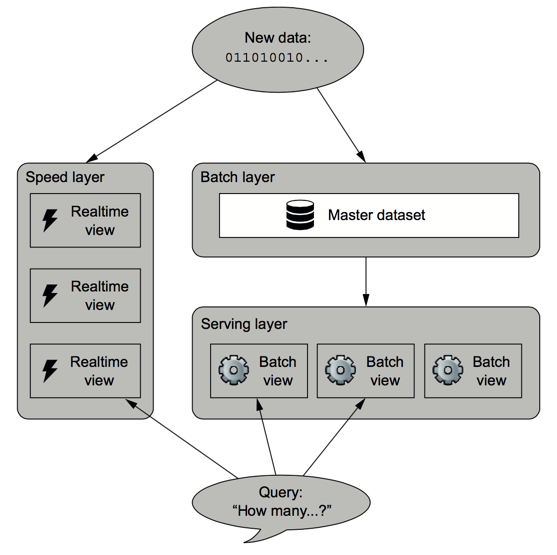
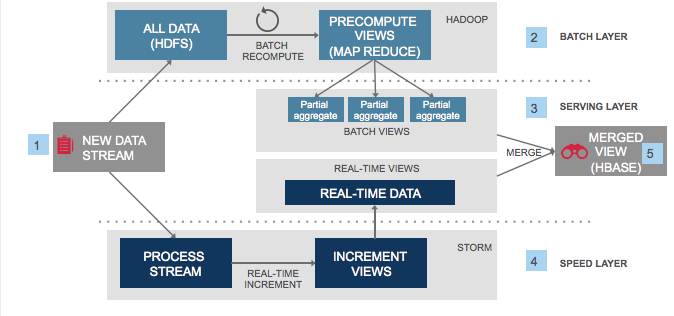
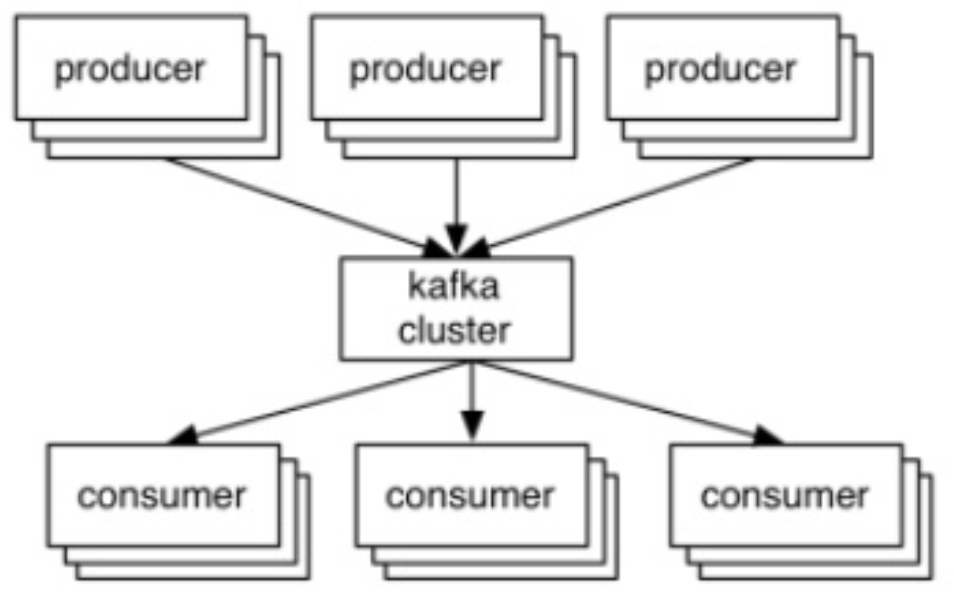
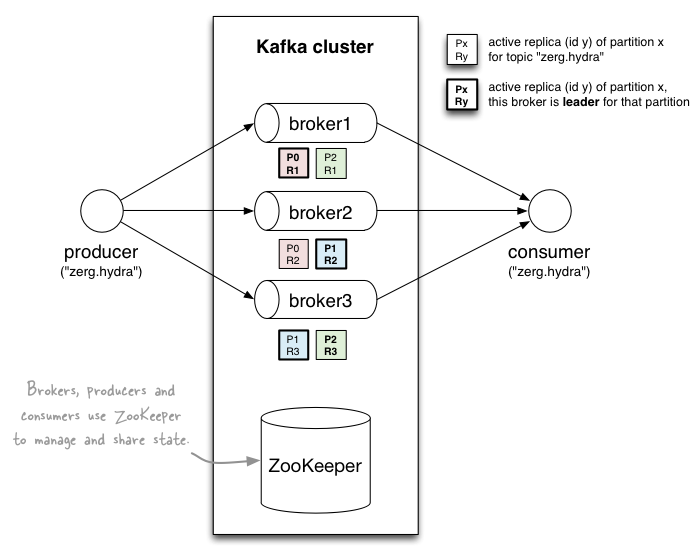
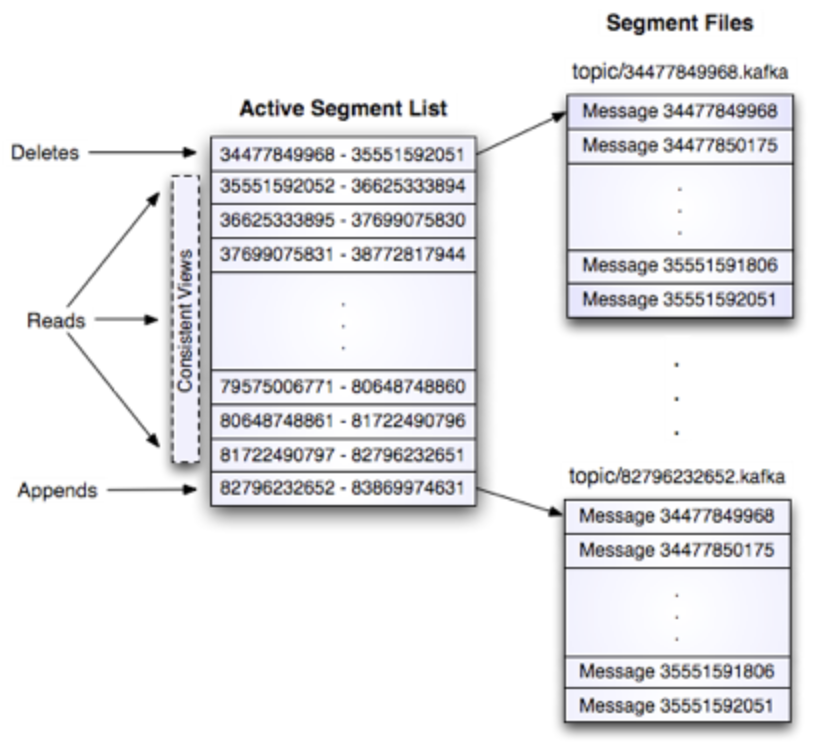
在一个常规的互联网服务中,读取与写入的比例大约是 100:1 到 1000:1。然而,从硬盘读取时,数据库连接操作耗时,99% 的时间花费在磁盘寻址上。更不用说跨网络的分布式连接操作了。
为了优化读取性能,非规范化通过添加冗余数据或分组数据来引入。这四种 NoSQL 类型可以帮助解决这个问题。
键值存储
键值存储的抽象是一个巨大的哈希表/哈希映射/字典。
我们希望使用键值缓存的主要原因是为了减少访问活跃数据的延迟。在快速且昂贵的介��质(如内存或 SSD)上实现 O(1) 的读/写性能,而不是在传统的慢且便宜的介质(通常是硬盘)上实现 O(logn) 的读/写性能。
设计缓存时需要考虑三个主要因素。
- 模式:如何缓存?是读透/写透/写旁/写回/缓存旁?
- 放置:将缓存放在哪里?客户端/独立层/服务器端?
- 替换:何时过期/替换数据?LRU/LFU/ARC?
现成的选择:Redis/Memcache?Redis 支持数据持久化,而 Memcache 不支持。Riak、Berkeley DB、HamsterDB、Amazon Dynamo、Project Voldemort 等等。
文档存储
文档存储的抽象类似于键值存储,但文档(如 XML、JSON、BSON 等)存储在键值对的值部分。
我们希望使用文档存储的主要原因是灵活性和性能。灵活性通过无模式文档实现,性能通过打破 3NF 来提高。初创公司的业务需求时常变化。灵活的模式使他们能够快速行动。
现成的选择:MongoDB、CouchDB、Terrastore、OrientDB、RavenDB 等等。
列式存储
列式存储的抽象就像一个巨大的嵌套映射:ColumnFamily<RowKey, Columns<Name, Value, Timestamp>>。
我们希望使用列式存储的主要原因是它是分布式的、高可用的,并且针对写入进行了优化。
现成的选择:Cassandra、HBase、Hypertable、Amazon SimpleDB 等等。
图数据库
顾名思义,这种数据库的抽象是一个图。它允许我们存储实体及其之间的关系。
如果我们使用关系数据库来存储图,添加/删除关系可能涉及模式更改和数据移动,而使用图数据库则不需要。另一方面,当我们在关系数据库中为图创建表时,我们是基于我们想要的遍历进行建模;如果遍历发生变化,数据也必须随之变化。
现成的选择:Neo4J、Infinitegraph、OrientDB、FlockDB 等等。