如何设计区块链服务端的架构?
需求分析
- 分布式的区块链记账和智能合约系统
- 节点之间相互不大信任,但是又需要激励他们互相合作
- 交易不可逆
- 不依赖可信的第三方
- 保护隐私,透露最少信息
- 不依赖中心化的权威证明一笔钱不能花两次
- 假设性能不是问题,暂不考虑如何优化性能
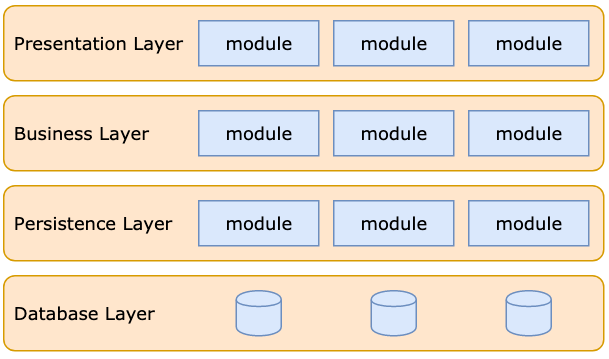
构架设计

具体模块和他们之间的交互
基础层(P2P 网络、加密算法、存储)
P2P 网络
分布式系统有两种实现方式:
- 中心化的 lead / follower 的分布式,比如 Hadoop, Zookeeper 这种系统,结构比较简单,但是对 lead 要求高
- 去中心化的对等 (P2P) 网络分布式,比如 Chord, CAN, Pastry, Tapestry 算法组织起来的网络,结构比较复杂,但是更加平��等
因为前提条件是节点之间不大信任,所以选择 P2P 的形式。具体到如何组织 P2P 的网络呢?一个典型的去中心化的节点和网络是这样保持连接的:
- 基于 IP 协议,节点上线占用某个地址 hostname/port,利用初始化的节点列表广播自己的地址,利用这些初始的 hop,试图向全网 flood 自己的信息
- 接到广播的初始节点一方面存下这个 neighbor,一方面帮助他 flooding,不相邻的节点收到后 NAT 穿墙加 neigbhor
- 节点之间 anti-entropy 随机互相 heartbeat 发出最新的带着类似 vector clock 的信息,保证能够持续更新对方那里自己的最新信息
我们可以利用既有的库,比如 libp2p,来实现网络模块。网络协议的选择见Crack the System Design Interview: Communication.
加密算法
在互相不大信任的分布式系统中,一笔转账如何在不泄漏自己秘密信息的同时证明这个转账是自己发起的呢?非对称加密:一对公钥和私钥对应一个”所有权”。Bitcoin 选择 secp256k1 参数的 ECDSA 椭圆曲线加密算法,为了兼容,其他链也基本选择同样的算法。
为什么不直接把公钥作为转账的地址呢?隐私问题,交易的过程应该尽可能少地泄漏信息,用公钥的哈希作为“地址”可以避免接��收方泄露公钥。甚至,人们应该避免反复使用同一个地址。
具体到账本的账户,有两种实现方式 UTXO vs. Account/Balance
- UTXO (unspent transaction output) ,例如 Bitcoin,类似于复式记账的 credit 和 debit,每个 transaction 有都有 input 和 output,但是除了 coinbase 每个 input 的前面都连着上一个的 output。尽管没有账户的概念,但是取一个地址对应的所有的未花完的 output,就是这个地址的余额。
- 优点
- 精准:类似于复式记账的结构,让流水账非常精准地记录下所有的资产流动。
- 保护隐私和抗量子攻击:如果用户经常换地址的话。
- 无状态:为提高并发留下了可能。
- 避免重放攻击:因为重放会找不到 input 对应的 UTXO
- 缺点
- 记录了所有的交易,复杂,消耗存储空间。
- 遍历 UTXO 花时间。
- 优点
- Account/Balance,例如 Ethereum,有三个主要的 map:account map, transaction map, transaction receipts map. 具体在实现上,为了缩减空间、防篡改,使用 merkle patricia trie (MPT)
- 优点
- 省空间:不像是 UTXO 那样,一个 transaction 把多个 UTXO 联系起来
- 简单:把复杂性让给了 script
- 缺点
- 需要用 nonce 解决重放问题,因为 transaction 之间没有依赖性
- 优点
值得一提的是 “区块 + 链” 的数据结构本质上来讲,就是 append-only 的 Merkle tree,也被称为 hash tree.
存储
因为本身 UTXO 或者 MPT 这种结构就充当了索引,加上分布式的时候,为了让每个节点运维更加简单,一般做 data persistence 的时候倾向于选择 in-process database 随着节点的程序能够直接跑,比如 LevelDB, RocksDB。
因为这种索引并不是通用的,所以你并不能像是 SQL 数据库那样查询,这也为数据分析提高了门槛,优化时需要专门做一个 indexer 服务,比如 etherscan。
协议层
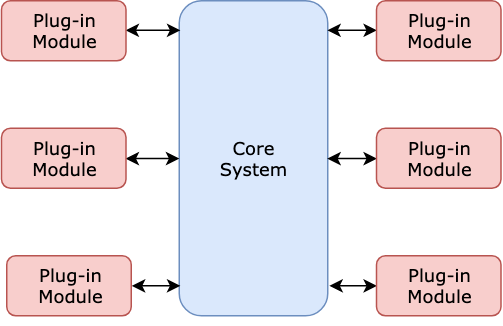
现在我们有了可以操作的基础层后,在这层之上,我们需要一个比较通用的逻辑操作的协议层。根据这个区块链的使用需求,可以像是微内核构架那样,插拔具体的逻辑处理模块。
比如最常见的记账:在最新的 block 高度收到了一些 transaction,组织起来建立如上一层构架所说的数据结构。
为每一个业务逻辑写一个原生模块然后更新所有节点的代码不大现实,用虚拟化的方法解耦这一层?答案是能够执行 smart contract 代码的虚拟机。在互不可信的环境中,不能让客户白执行代码,所以这个虚拟机最独特的功能可能是计费。
基于 contract 的 token 比如 ERC20 和 native token 的区别,导致在不同的 token 捣腾的时候很麻烦,于是就出现了 Wrapped Ether 这种 token.
共识层
协议层算出来执行的结果之后,如何跟其他的节点达成一致呢?有如下一些常见的激励大家合作的机制:
- proof of work (POW): 用 hash 的碰撞挖 token,耗电量大不环保
- proof of stake (POS): 用质押的 token 挖 token
- delegated proof-of-stake (DPOS): 选人民代表用质押的 token 挖 token
在激励机制的基础上,节点中谁的链最长听谁的,两群人互不待见就分叉。
同时,有这样一些一致性协议让大家达成共识(也就是大家要么一起都干,要么一起都不干)
- 2PC:大家都依赖某一个 coordinator:coordinator 问大家:要不要干?只要有人回复不干,那么 coordinator 跟所有人都说“不干”;否则都说干。 这样的依赖会导致,如果 coordinator 在第二个阶段的中间挂了,有些节点会不知道怎么办 block 在那里,需要人工干预重启 coordinator。
- 3PC:为了解决上述问题,加一个保证大家在干之前都知道所有人要干还是不干的阶段,出了错就重新选 coordinator
- Paxos:上述的 2PC 和 3PC 都依赖某一个 coordinator,如何干掉这个 coordinator 呢?用“大多数(2f + 1 里至少 f+1)”来取代,在两步中,只要大多数取得一致,最后就能取得一致。
- PBFT (deterministic 3-step protocol): 上述的做法容错率还是不够高,于是有了 PBFT。用来保证大多数(2 / 3)节点要么都同意,要么都不同意的算法,具体做法是三轮投票,每轮有至少大多数(2 / 3)节点同意,最后一轮才 commit block 。
在具体的应用中,关系数据库大多用 2PC 或者 3PC ;Paxos 的变种有 Zookeeper 的实现,Google Chubby 分布式锁的实现,Spanner 的实现;区块链中,Bitcoin, Ethereum 是 POW,新的 Ethereum 是 POS,IoTeX 和 EOS 是 DPOS。