Netflix 如何提供观看数据?
动机
如何在规模上保持用户的观看数据(每天数十亿事件)?
在这里,观看数据指的是...
- 观看历史。我看过哪些标题?
- 观看进度。我在某个标题中停留在哪里?
- 正在观看的内容。我的账户现在还在观看什么?
架构
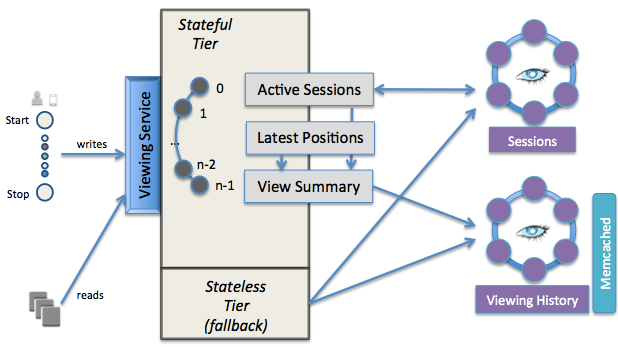
观看服务有两个层次:
-
有状态层 = 活动视图存储在内存中
- 为什么?为了支持最高的读/写量
- 如何扩展?
- 按照
account_id mod N分区为 N 个有状态节点- 一个问题是负载分布不均,因此系统容易出现热点
- 在 CAP 定理 下选择 CP 而非 AP,并且没有活动状态��的副本。
- 一个失败的节点将影响
1/n的成员。因此,他们使用过时的数据以优雅地降级。
- 一个失败的节点将影响
- 按照
-
无状态层 = 数据持久性 = Cassandra + Memcached
- 使用 Cassandra 进行非常高的写入量和低延迟。
- 数据均匀分布。由于使用虚拟节点进行一致性哈希来分区数据,因此没有热点。
- 使用 Memcached 进行非常高的读取量和低延迟。
- 如何更新缓存?
- 在写入 Cassandra 后,将更新的数据写回 Memcached
- 最终一致性,以处理多个写入者,具有短的缓存条目 TTL 和定期的缓存刷新。
- 将来,优先考虑 Redis 的追加操作到时间排序列表,而不是 Memcached 中的“读-修改-写”。
- 如何更新缓存?
- 使用 Cassandra 进行非常高的写入量和低延迟。