设计负载均衡器或 Dropbox 修补程序
需求
互联网规模的网络服务处理来自全球的高流量。然而,单个服务器在同一时间只能处理有限数量的请求。因此,通常会有一个服务器集群或大型服务器集群来共同承担流量。问题来了:如何路由这些请求,以便每个主机能够均匀地接收和处理请求?
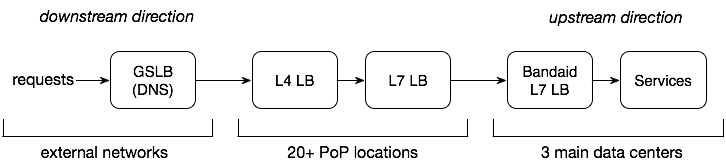
由于从用户到服务器之间有许多跳数和负载均衡器层,因此这次我们的设计要求是
- 在数据中心设计 L7 负载均衡器
- 利用来自后端的实时负载信息
- 每秒处理 10 万 RPS,10 TB 流量
注意:如果服务 A 依赖于(或消费)服务 B,则 A 是 B 的下游服务,而 B 是 A 的上游服务。
挑战
为什么负载均衡很难?答案是很难收集准确的负载分布统计数据并相应地采取行动。
按请求分配 ≠ 按负载分配
随机和轮询通过请求分配流量。然而,实际负载并不是每个请求 - 有些在 CPU 或线程利用率上很重,而有些则很轻。
为了更准确地评估负载,负载均衡器必须维护每个后端服务器的观察到的活动请求数量、连接数量或请求处理延迟的本地状态。基于这些信息,我们可以使用诸如最少连接、最少时间和随机 N 选择等分配算法:
最少连接:请求被传递给活动连接数最少的服务器。
基于延迟(最少时间):请求被传递给平均响应时间最少和活动连接数最少的服务器,同时考虑服务器的权重。
然而,这两种算法仅在只有一个负载均衡器的情况下效果良好。如果有多个负载均衡器,可能会出现 羊群效应。也就是说,所有负载均衡器都注意到某个服务瞬时更快,然后都向该服务发送请求。
随机 N ��选择(在大多数情况下 N=2 / 也称为 二选一的力量):随机选择两个并选择两个中的更好选项,避免选择更差的选项。
分布式环境
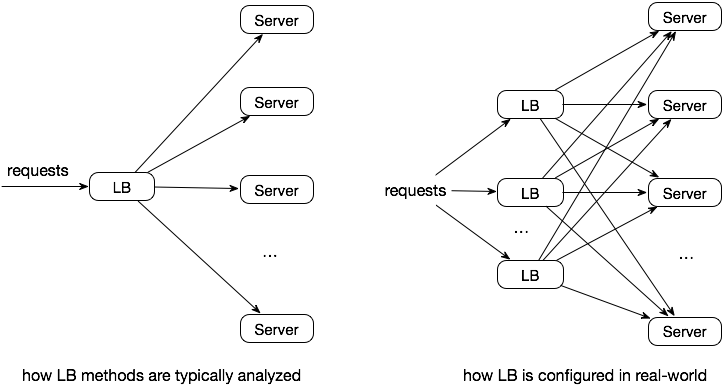
本地负载均衡器对全局下游和上游状态并不知情,包括
- 上游服务负载
- 上游服务可能非常庞大,因此很难选择正确的子集来覆盖负载均衡器
- 下游服务负载
- 各种请求的处理时间很难预测
解决方案
有三种选项可以准确收集负载统计数据,然后采取相应的行动:
- 集中式和动态控制器
- 分布式但具有共享状态
- 在响应消息或主动探测中附加服务器端信息
Dropbox Bandaid 团队选择了第三种选项,因为它很好地适应了他们现有的 随机 N 选择 方法。
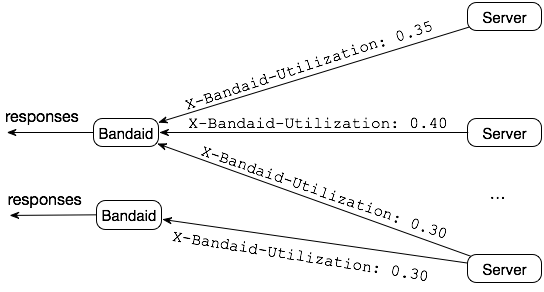
然而,他们并没有像原始的 随机 N 选择 那样使用本地状态,而是通过响应头使用来自后端服务器的实时全局信息。
服务器利用率:后端服务器配置了最大容量并计算正在进行的请求,然后计算利用率百分比,范围从 0.0 到 1.0。
需要考虑两个问题:
- 处理 HTTP 错误:如果服务器快速失败请求,它会吸引更多流量并导致更多失败。
- 统计衰减:如果服务器的负载过高,则不会将请求分配到该服务器,因此服务器会被卡住。他们使用反向 sigmoid 曲线的衰减函数来解决此问题。
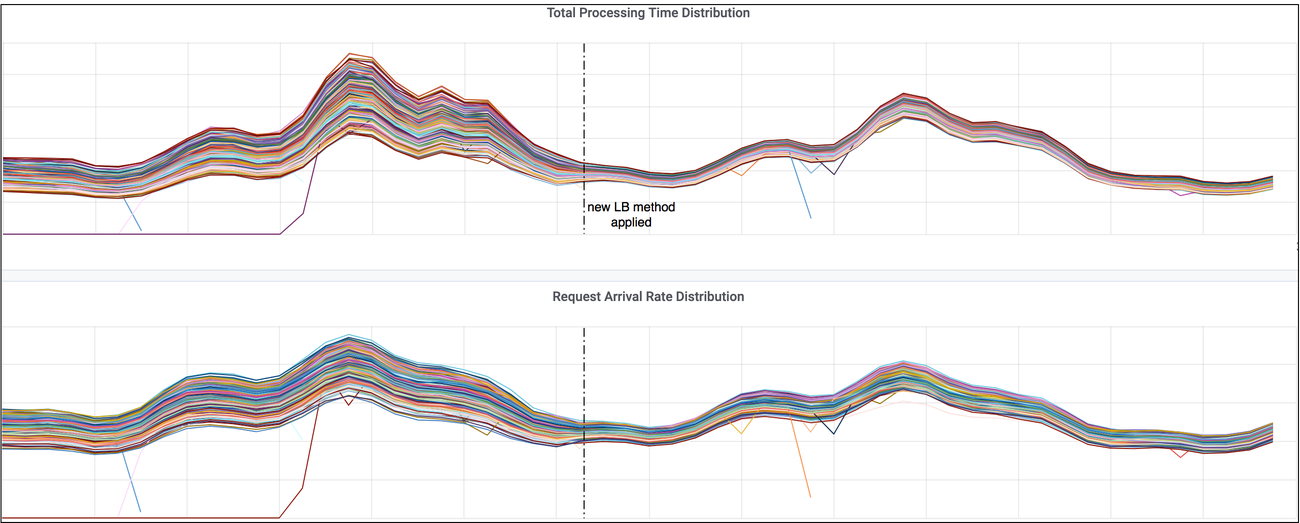
结果:请求更加均衡
- https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
- https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
- https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn