How Netflix Serves Viewing Data?
Motivation
How to keep users' viewing data in scale (billions of events per day)?
Here, viewing data means...
- viewing history. What titles have I watched?
- viewing progress. Where did I leave off in a given title?
- on-going viewers. What else is being watched on my account right now?
Architecture
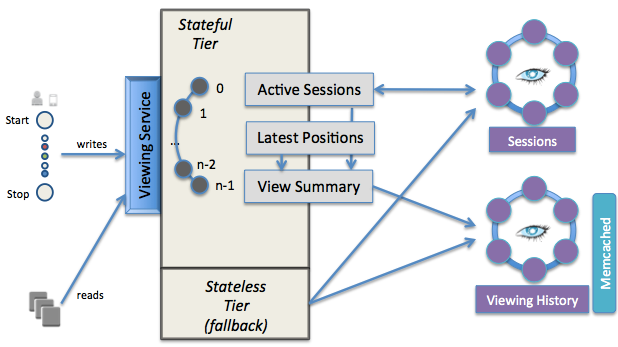
The viewing service has two tiers:
-
stateful tier = active views stored in memory
- Why? to support the highest volume read/write
- How to scale out?
- partitioned into N stateful nodes by
account_id mod N- One problem is that load is not evenly distributed and hence the system is subject to hot spots
- CP over AP in CAP theorem, and there is no replica of active states.
- One failed node will impact
1/nthof the members. So they use stale data to degrade gracefully.
- One failed node will impact
- partitioned into N stateful nodes by
-
stateless tier = data persistence = Cassandra + Memcached
- Use Cassandra for very high volume, low latency writes.
- Data is evenly distributed. No hot spots because of consistent hashing with virtual nodes to partition the data.
- Use Memcached for very high volume, low latency reads.
- How to update the cache?
- after writing to Cassandra, write the updated data back to Memcached
- eventually consistent to handling multiple writers with a short cache entry TTL and a periodic cache refresh.
- in the future, prefer Redis' appending operation to a time-ordered list over "read-modify-writes" in Memcached.
- How to update the cache?
- Use Cassandra for very high volume, low latency writes.