Designing Memcached or an in-memory KV store
Requirements
- High-performance, distributed key-value store
- Why distributed?
- Answer: to hold a larger size of data

- Answer: to hold a larger size of data
- For in-memory storage of small data objects
- Simple server (pushing complexity to the client) and hence reliable and easy to deploy
Architecture
Big Picture: Client-server
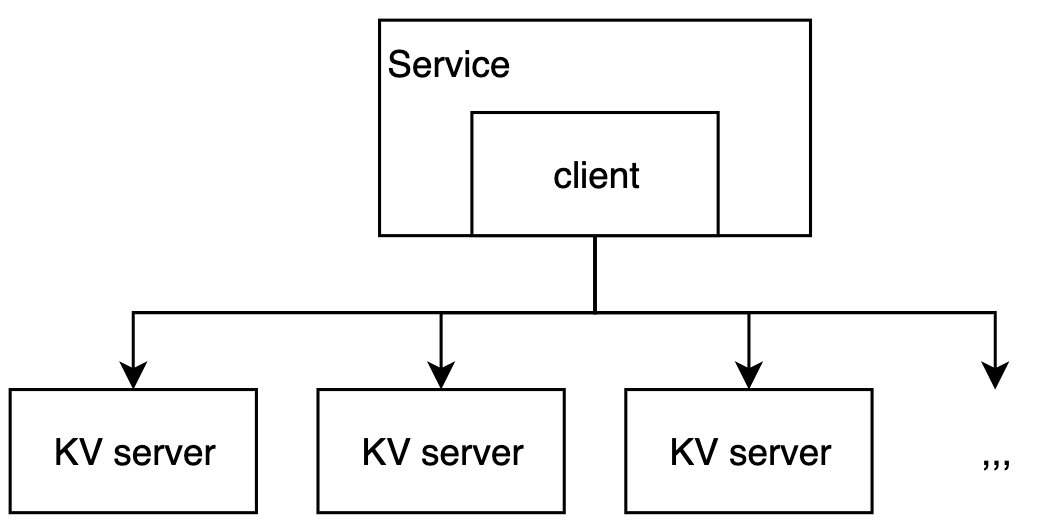
- client
- given a list of Memcached servers
- chooses a server based on the key
- server
- store KVs into the internal hash table
- LRU eviction
The Key-value server consists of a fixed-size hash table + single-threaded handler + coarse locking
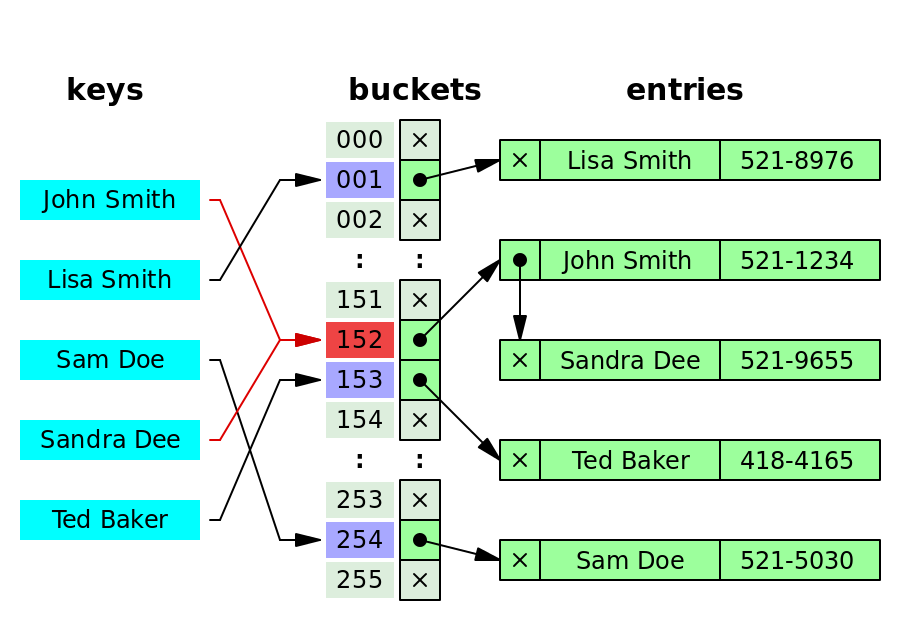
How to handle collisions? Mostly three ways to resolve:
- Separate chaining: the collided bucket chains a list of entries with the same index, and you can always append the newly collided key-value pair to the list.
- open addressing: if there is a collision, go to the next index until finding an available bucket.
- dynamic resizing: resize the hash table and allocate more spaces; hence, collisions will happen less frequently.
How does the client determine which server to query?
See Data Partition and Routing
How to use cache?
See Key value cache